Back to Lecture Thumbnails

jennaruzekowicz

alexder
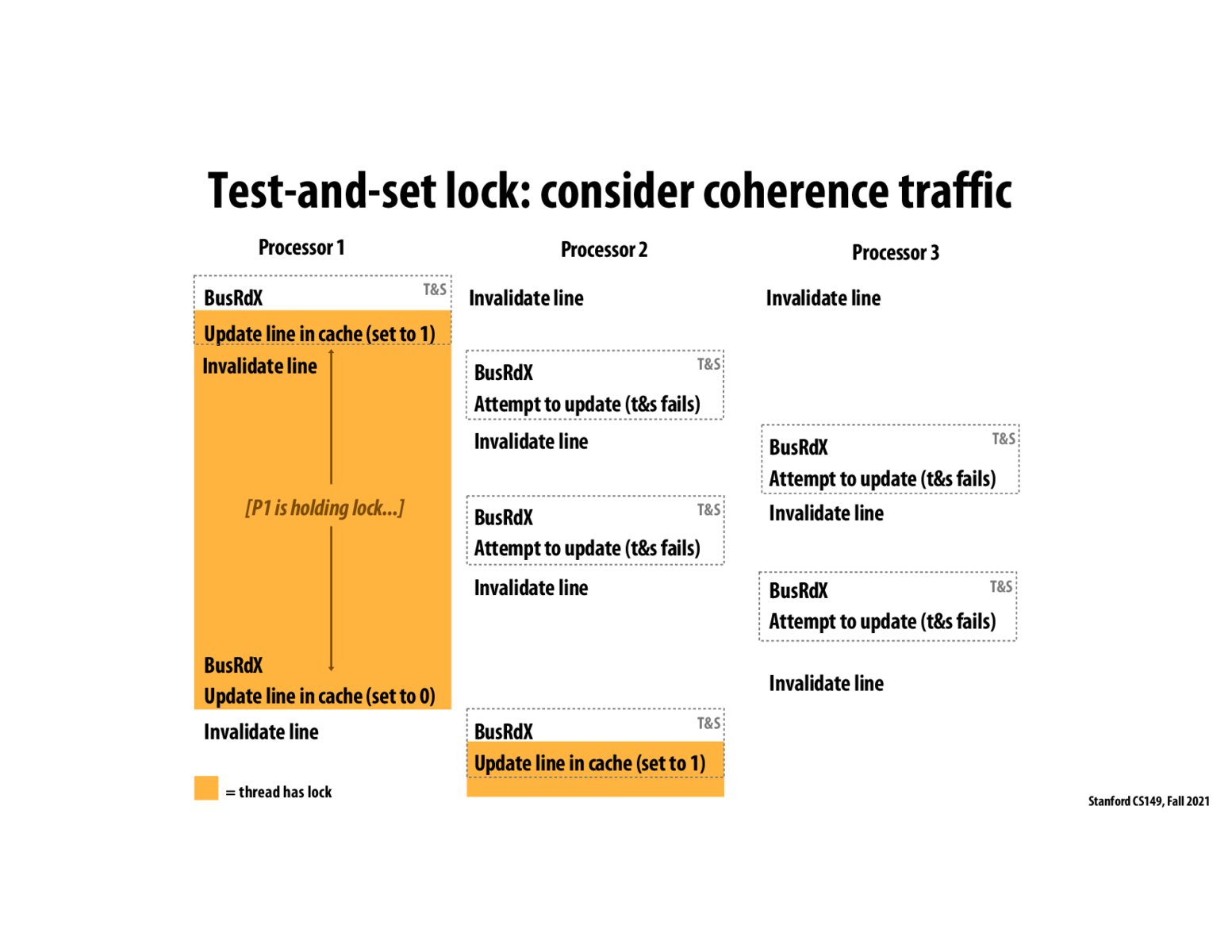
Is the reason that this is a suboptimal design that Processes 2 and 3 are constantly tryin to acquire the lock from Processor 1, so in some sense, they are getting time on the CPU to perform this operation that would otherwise be used processor 1 entirely.
Please log in to leave a comment.
In comparison to slide 69, we see that we gain a huge advantage by not issuing a BusRdX every time we attempt to pick up the lock. This directly ties back into the concept from earlier in the lecture that we do not want to swarm the bus with useless requests! This prevents work from being done within other processors. Although not a deadlock or livelock, this scenario can greatly slow down the speed of execution. As seen in slide 69, it is better that we allow a shared state that does not swarm the bus with requests. If the data that is wished to be accessed is shared, then there is no need to broadcast to the other processors when a check is being done.