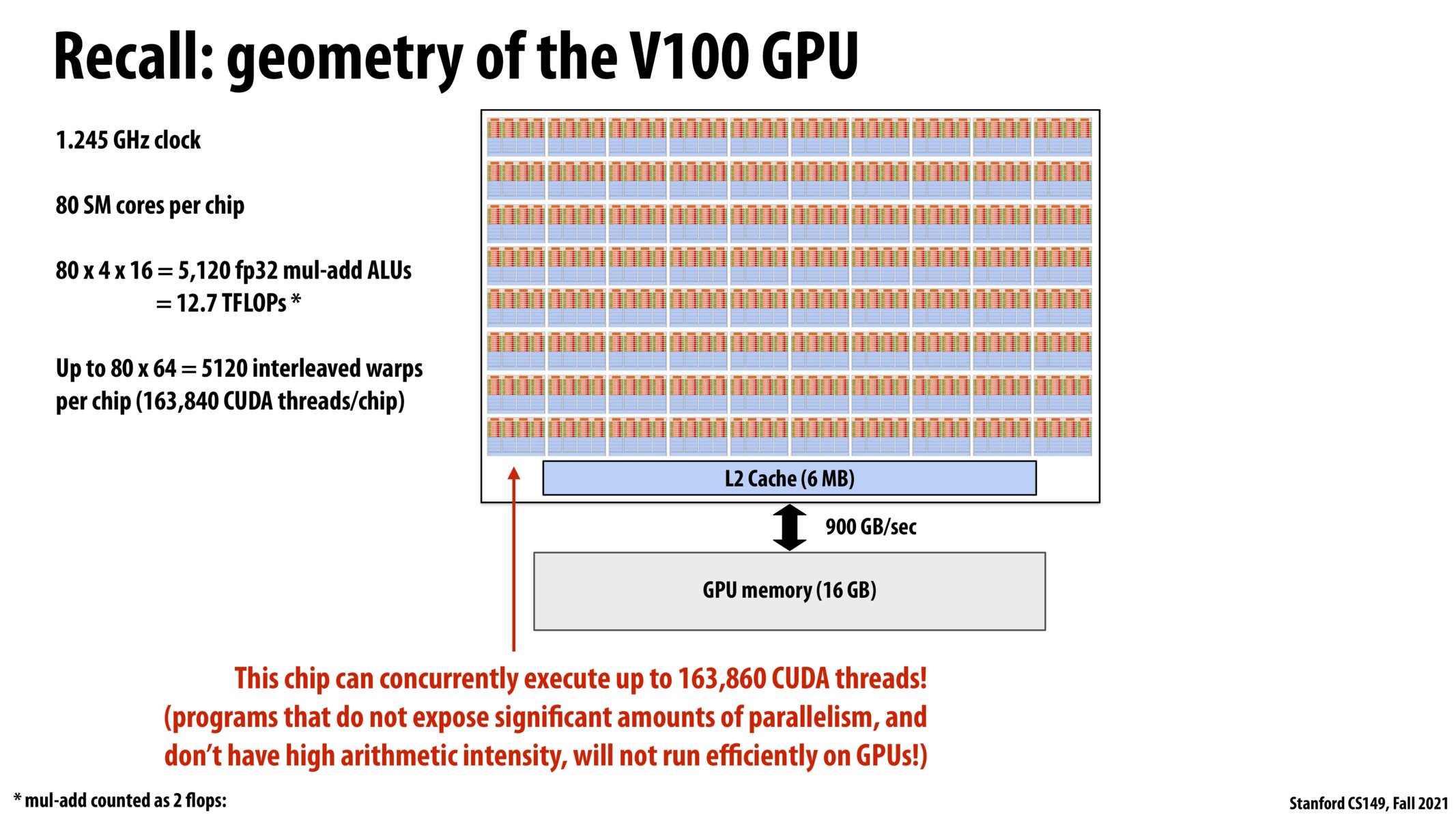


Why not have a bigger cache? What's the point of having so much computing power if you can't usually efficiently load the memory it needs. Wouldn't it be better to split up the 80 SM cores and give them their own Cache.

I've also been confused by this, both in this case and for CPUs. Is there not a lot of demand for either larger caches or more/wider buses to increase throughput?

How does this v100 GPU fit into a larger computer architecture? Would you ever find a chip like this on a consumer laptop, or would it be present only in a server farm or other larger infrastructure?

@evs @csmith23 I think these are great questions. I would wager that hardware designers find quickly diminishing returns from adding caches: think about it, if you have poor locality, it's not like doubling a 6MB cache to 12MB will make much of a difference. Also, I think SRAM (in caches) is pretty expensive. (Incidentally, I imagine it's harder to brag about the cache sizes than about all these TFLOPs.)

@rthomp Chips like the V100 are only really found in server farms because they use lots of power, and thus require significant cooling. Furthermore, most people don't require massive parallel computing capabilities on their laptops*.
*Mobile chips still have very parallel components which have specific purposes, like the neural engine in iphones but it is more aimed at power savings as opposed to raw compute power.

So from my understanding, warps are only interleaved if they're on the same sub-core because the fetch/decode unit chooses from warps on the sub-core. Is this correct? The wording that there are 5120 interleaved warps per chip is a bit confusing.

@evs @csmith23, Large we make caches, slower they get. This is dictated by the physical capabilities of the circuits we use to implement them. Moreover, caches are really expensive in terms of area and power. So, in an ideal world, if we didn't have to pay the price of increased latency, area, and power, we would 100% had large caches.
Please log in to leave a comment.
The size and execution power of this chip, i.e. the fact that it can run 163,860 CUDA threads, further proves the importance of creating software that fully utilizes the hardware provided. I think one of the most applicable topics, drawing in the example we saw in written assignment 2, is the use of rolling out instructions. I can see how for certain applications possibly with a chip with this much thread power, we would need to highly parallelize the code in anyway we can.