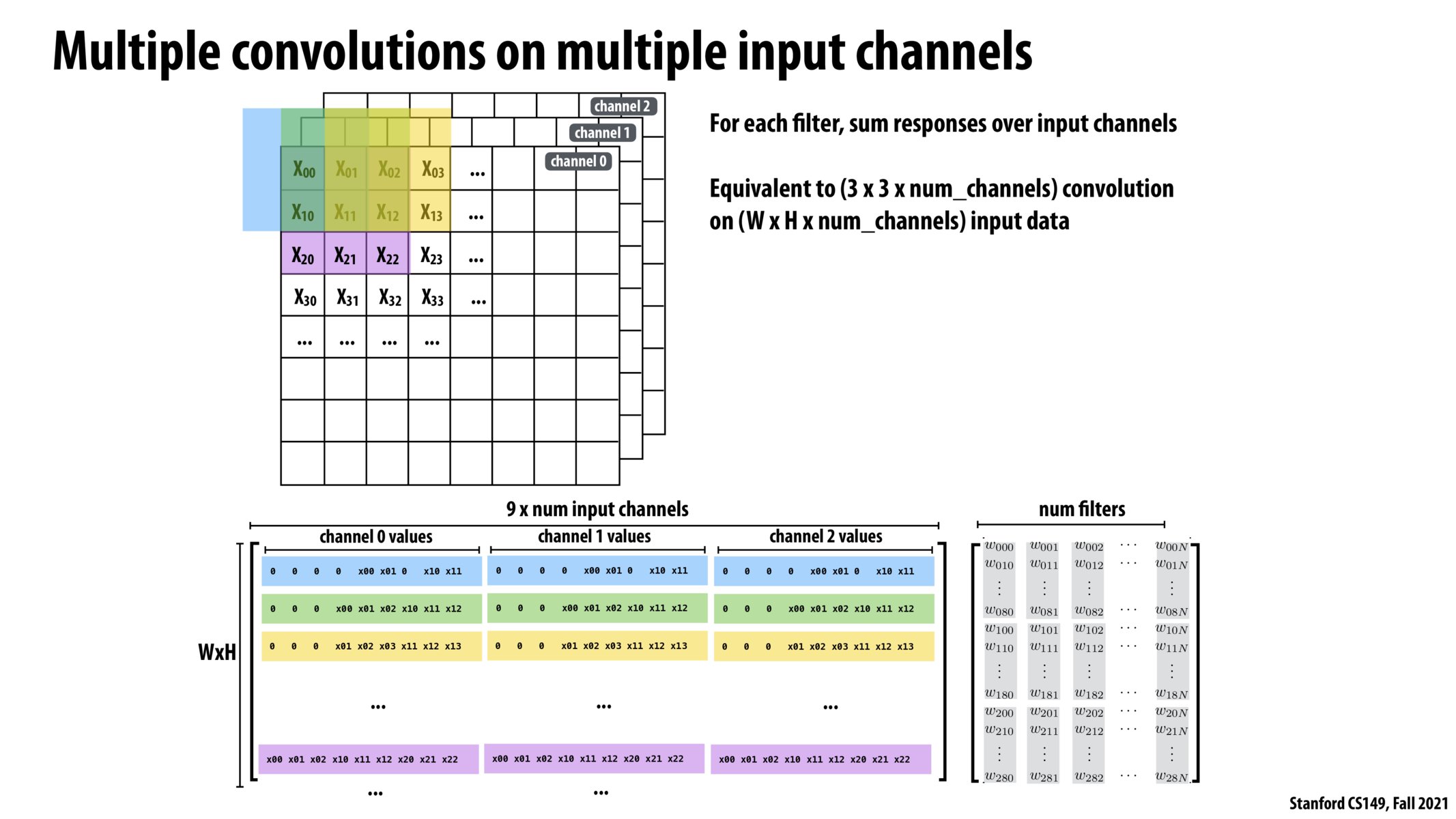


@rubensl You are right that this rearrangement has to be done on each input image before applying a convolution. Furthermore, if you have multiple convolution layers in a model, you would have to redo this process before each convolution since the output is a single vector of length WxH. In early implementations, this still seemed to have better performance overall due to the efficiency of GEMM. But as Kayvon mentioned, this technique is outdated, and engineers prefer to optimize the 7-for-loop implementation instead.
I think the point of these slides is to demonstrate that reformulating a problem to harness a different optimized algorithm (such as GEMM) can be an outside-the-box way to achieve high performance.
Please log in to leave a comment.
Is rearranging the image to this column layout have a tradeoff when looking at it from a performance standpoint apart from the larger memory usage? This would have to be done on each input image before applying a convolution using a GEMM operation.