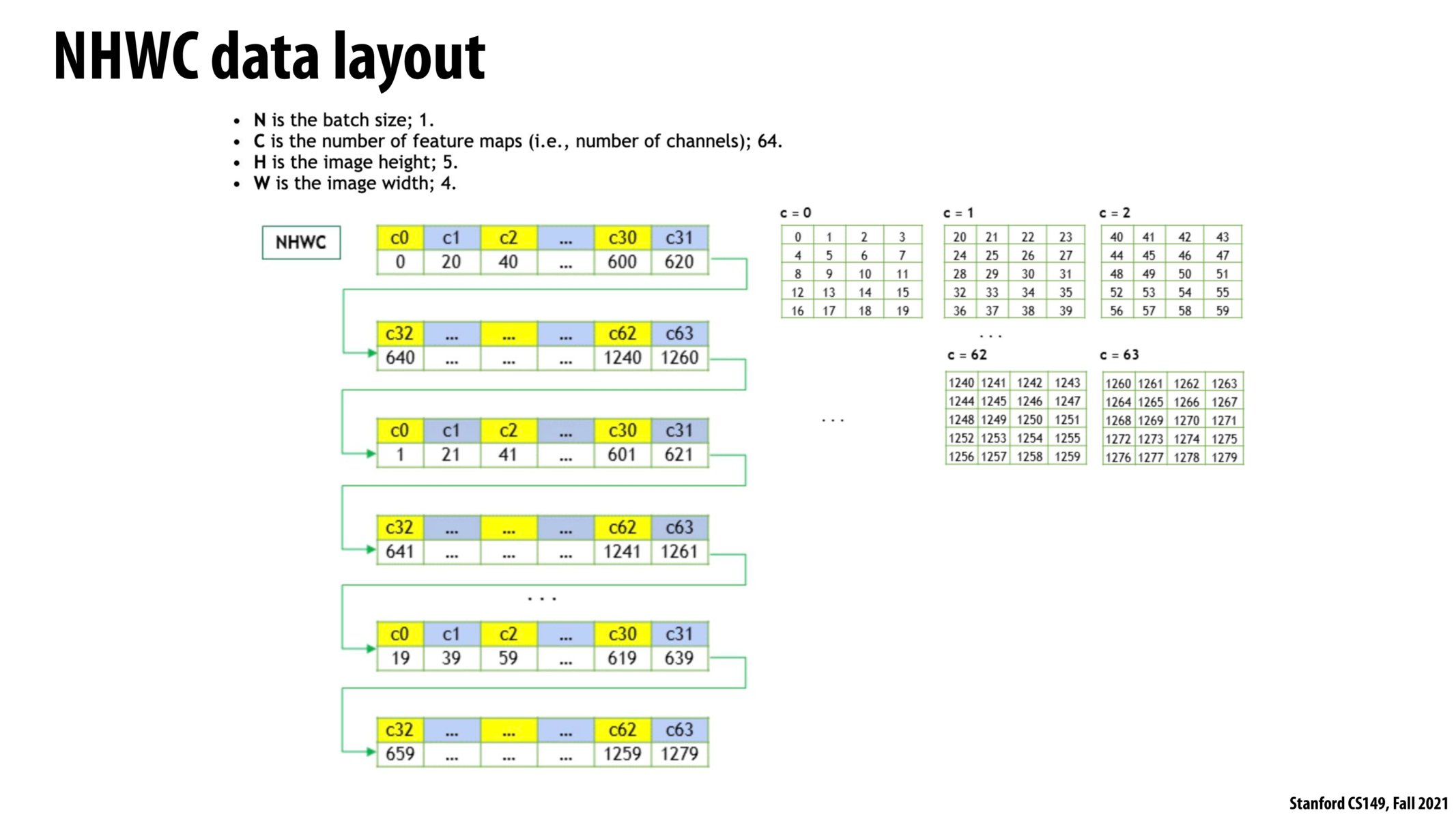

Yes, NHWC has better cache performance for the reason you mention, and another benefit is that it allows for vectorized math to be used. Any operation that you want to do on an input tensor may be the same operation you want to do across all channels (channel broadcasting), so this operation can be SIMD vectorized along this dimension. NCHW is considered a legacy mistake and often in deep learning compilers, an NCHW tensor may be transposed to be NHWC (through some copy operations), and then the vectorized operation may take place on an NHWC tensor to improve performance.

As someone from an AI background, I didn't previously understand why pytorch/tensorflow convert NCHW inputs to NHWC before applying various image operations, but this makes total sense. I find it fascinating how well-optimized these libraries are (especially having tried to implement my own vectorized convolutions before and still ending up considerably slower).
Please log in to leave a comment.
This interleaving strategy seems better than NCHW for cache performance because we tend to work on all channels at once. In NCHW the different channels are spread out in memory.