Back to Lecture Thumbnails

ckk

schaganty
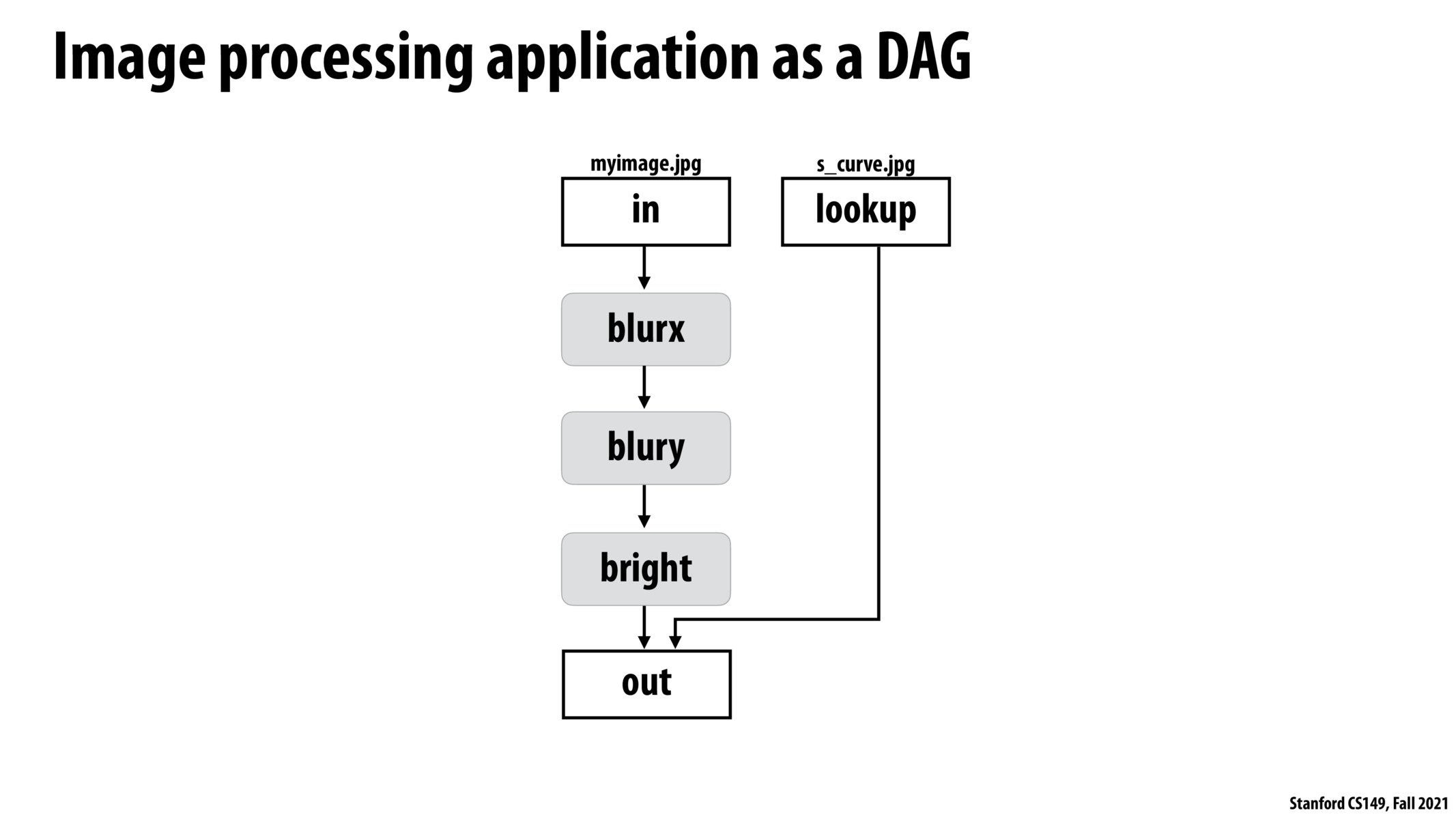
Similar to how a superscalar processor constructs a dependency graph of instructions to find independent instructions that can be executed in parallel, I wonder if one of the optimizations the halide auto-scheduler does is to search for operations in the pipeline that are independent and run them in parallel to speed up execution.
Please log in to leave a comment.
Halide is similar to the spark RDD abstraction, in that it spells out the order in which a sequence of operations should be performed, but that doesn't say how those individual operations should be implemented