Back to Lecture Thumbnails

shivalgo

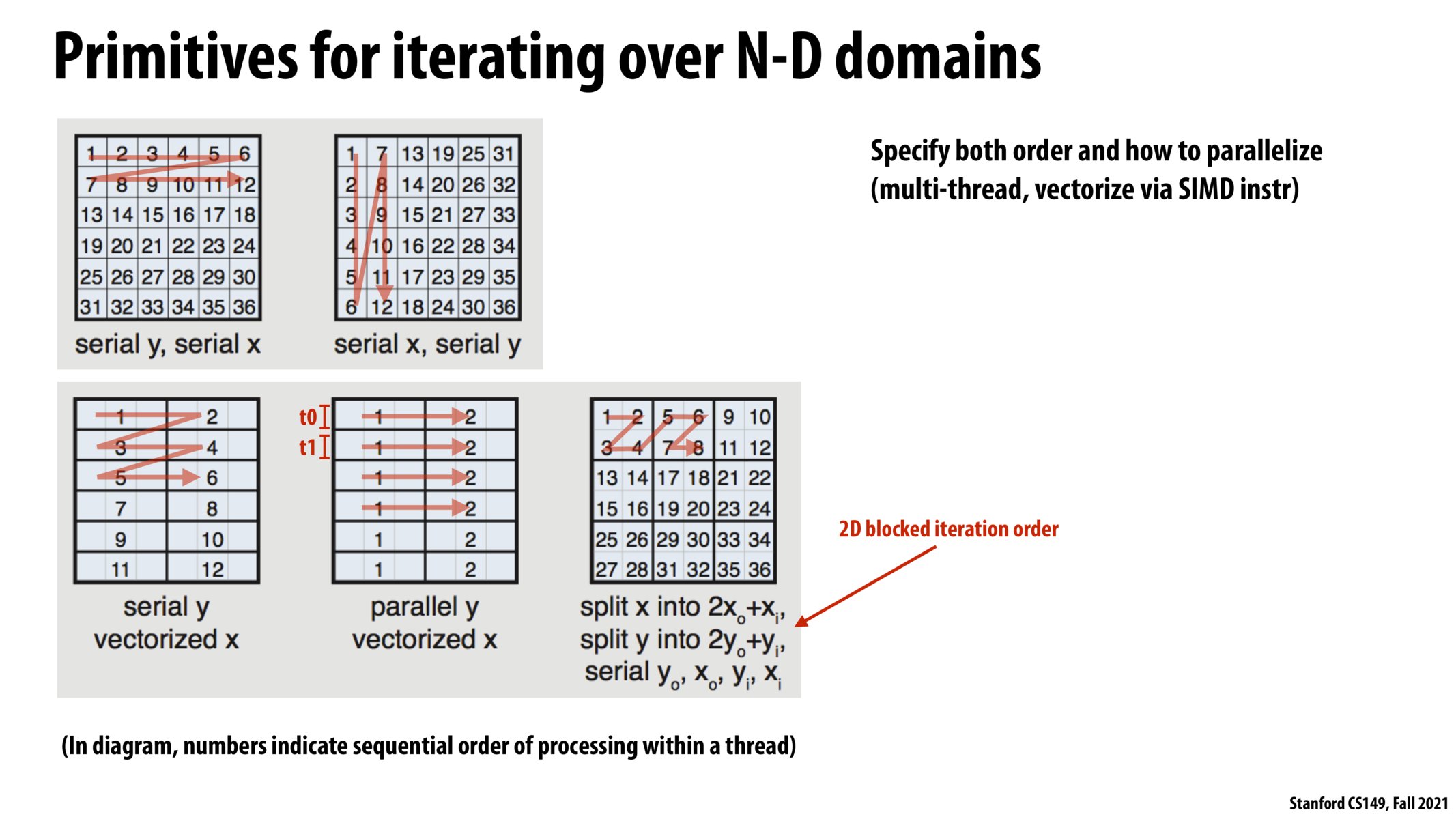
woo
i am a bit confused about the notation here. why does serial y, serial x generate different sequence than serial x, serial y ?

shaan0924
@woo I think the way to look at this is that serial y serial x refers to a nested loop with y on the outside and x on the inside. So for part one it becomes for(int y ...) { for(int x ... {} } whereas part two would be for(int x ...) { for(int y ...) {} }.

kai
@shivalgo Halide is able to produce both CUDA and OpenCL code with a few syntax changes to the scheduling code.
Please log in to leave a comment.
Looks like we may be able to do a similar implementation in CUDA by looping as chunks of 8 threads (and making 8 threads compute in parallel) on BlockDim.x with the effect being similar to an 8-wide SIMD and then parallelizing on BlockDim.y as usual? One thing I am pondering is can CUDA optimize for GPU cache locality by suggesting the right shared memory size automatically like Halide does? Because in PA3 we had to write code explicitly around making the array fit within a 64kb shared memory. Given the similarities, it looks like under the hood, Halide can without much fuss produce CUDA C/C++ code?