This seems less than ideal in terms of utilization, since more interleaving = more arithmetic work to hide the latency of the 3 memory ops that this program does?
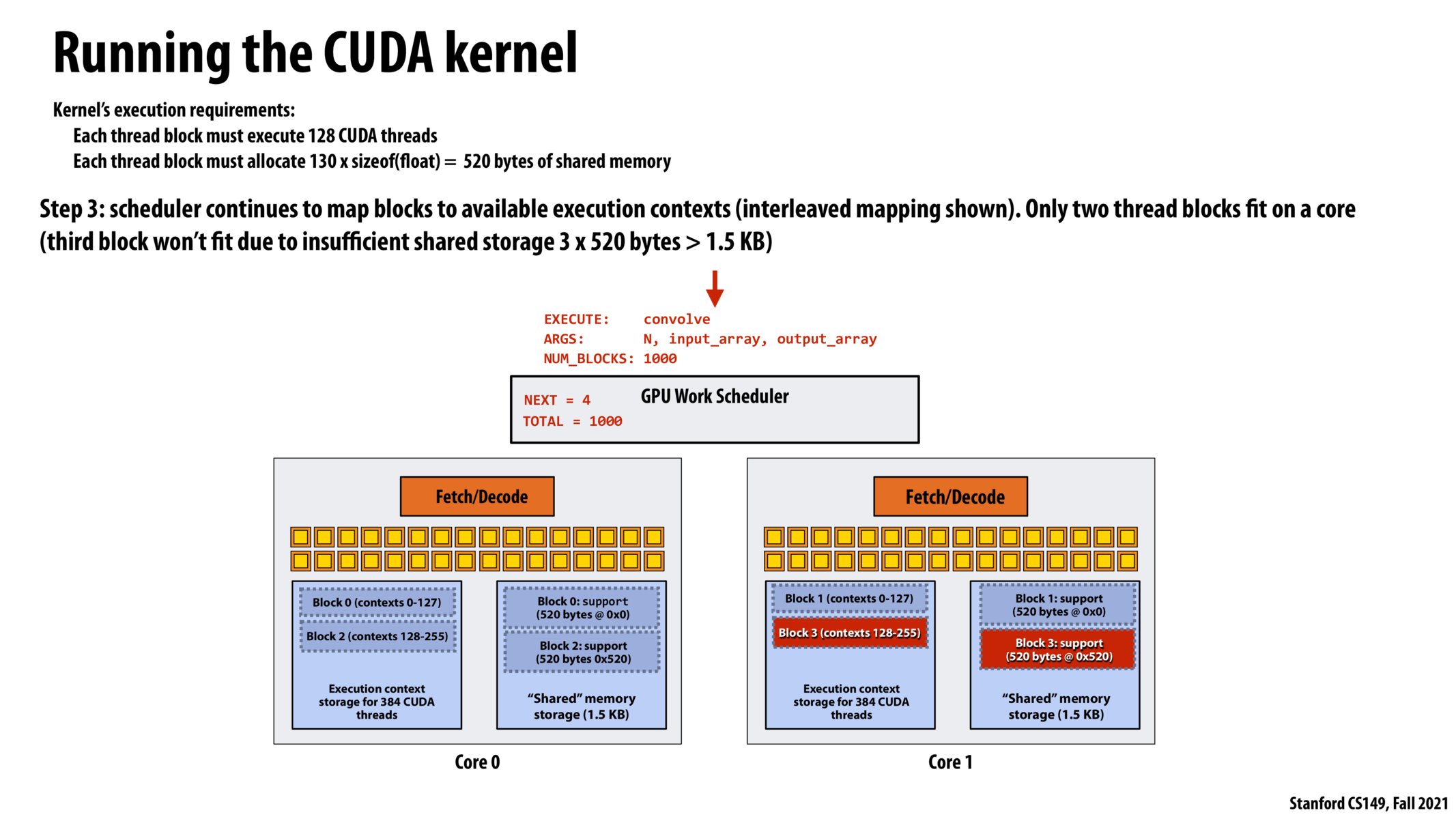
It seems like it makes sense to keep in the back of our minds the shared memory requirements per thread block compared with the shared memory storage per core. i.e., we definitely think about making the number of threads per thread block a multiple of warp size; would also be nice to be able to fill all execution contexts and not be limited by memory here.

This seems less than ideal in terms of utilization, since more interleaving = more arithmetic work to hide the latency of the 3 memory ops that this program does?
It seems like it makes sense to keep in the back of our minds the shared memory requirements per thread block compared with the shared memory storage per core. i.e., we definitely think about making the number of threads per thread block a multiple of warp size; would also be nice to be able to fill all execution contexts and not be limited by memory here.