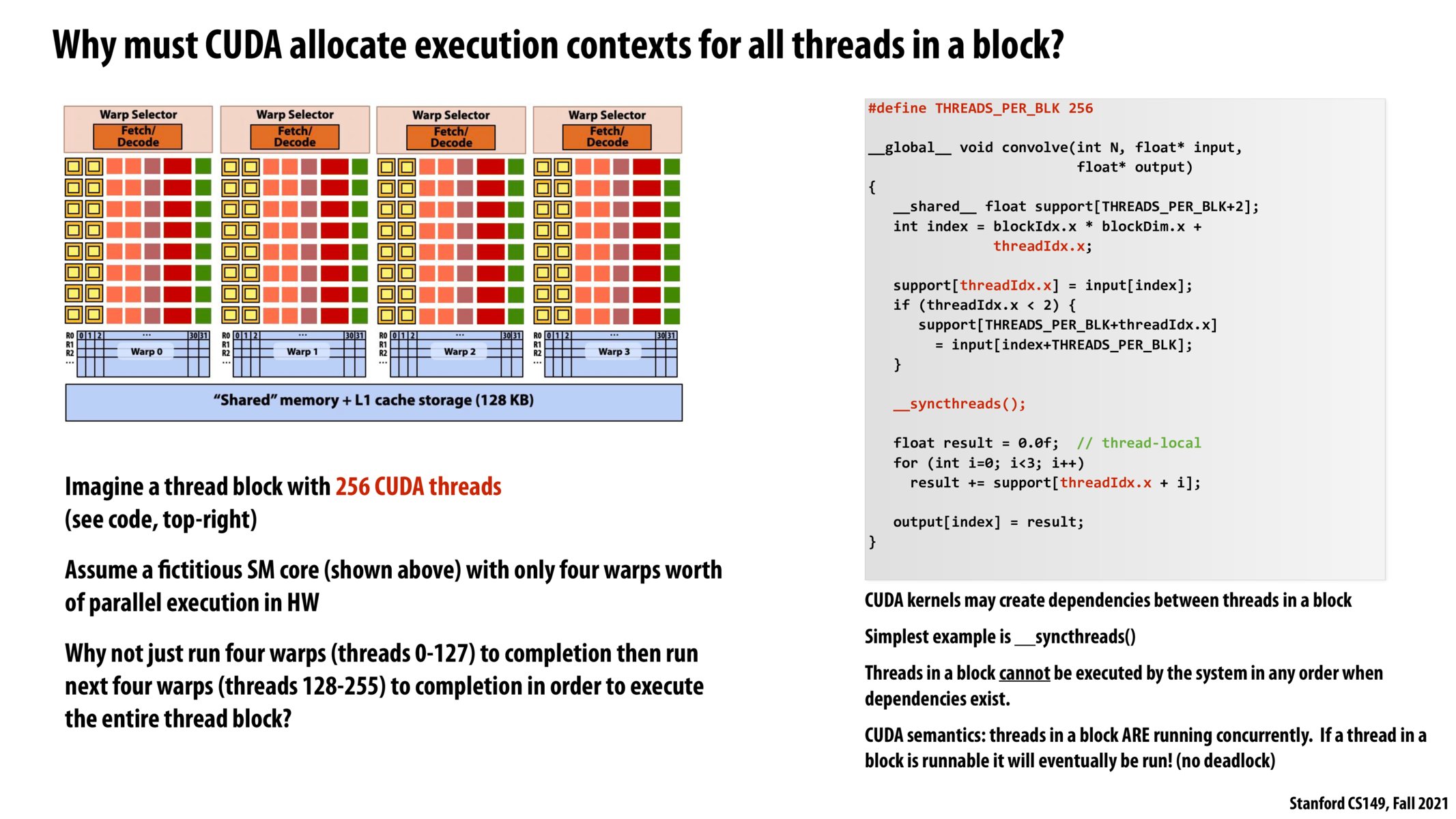


The answer from lecture is that running 4 warps to completion then running the next 4 warps will run into deadlock because _syncthreads() is a barrier that will stop each thread until all threads have reached that point, so the first 128 threads will not get off the processor and the last 128 threads will not get to run.

Extending @pizza's point - Threadblocks can be treated independently. But threads within a same block cannot be treated as independent because they work co-operatively and synchronize through things like syncThreads() which try to run all the threads in the block concurrently.

A generic example of scheduling:
Consider the problem of scheduling B thread blocks, each of which contains T threads, across C cores (each core has execution context storage for threads in terms of warps, shared memory for threads, and operates based on warp-level SIMD).
The scheduler begins by scheduling thread block 1 on core 1, so that T threads (and T / WARP_SIZE) warps are used on core 1. It then schedules thread block 2 on core 2, and continues this process. It does so, going from cores 1..C, and then back again to 1, as long as there are (a) enough execution contexts for a given thread block on a core, and (b) there is enough room in shared memory.

Adding on to @pizza's answer, we can't __syncthreads() on half of the threads in the block and try to run the other half afterwards because __syncthreads() operates on all 256 threads in the block. It would be impossible to run 0-127 threads and then run 128-255 after because all these threads are in the same block.

@jkuro I think one way to solve this would be to actually split the job into two separate CUDA kernels. Once one task has launched and completed running the first 128 threads, then you can launch another job for the remaining 256 threads. I think that this performs the same functionality as calling _syncthreads() halfway into the program but within the scope of CUDA functionality.
Please log in to leave a comment.
There is also a point mentioned during lecture that CUDA does not implement context switching for thread blocks because the goal of GPU programming is performance that could not be compromised if warps are frequently swapped to global memory. As a result, the size of a thread block is limited to the number of execution contexts on a SM.