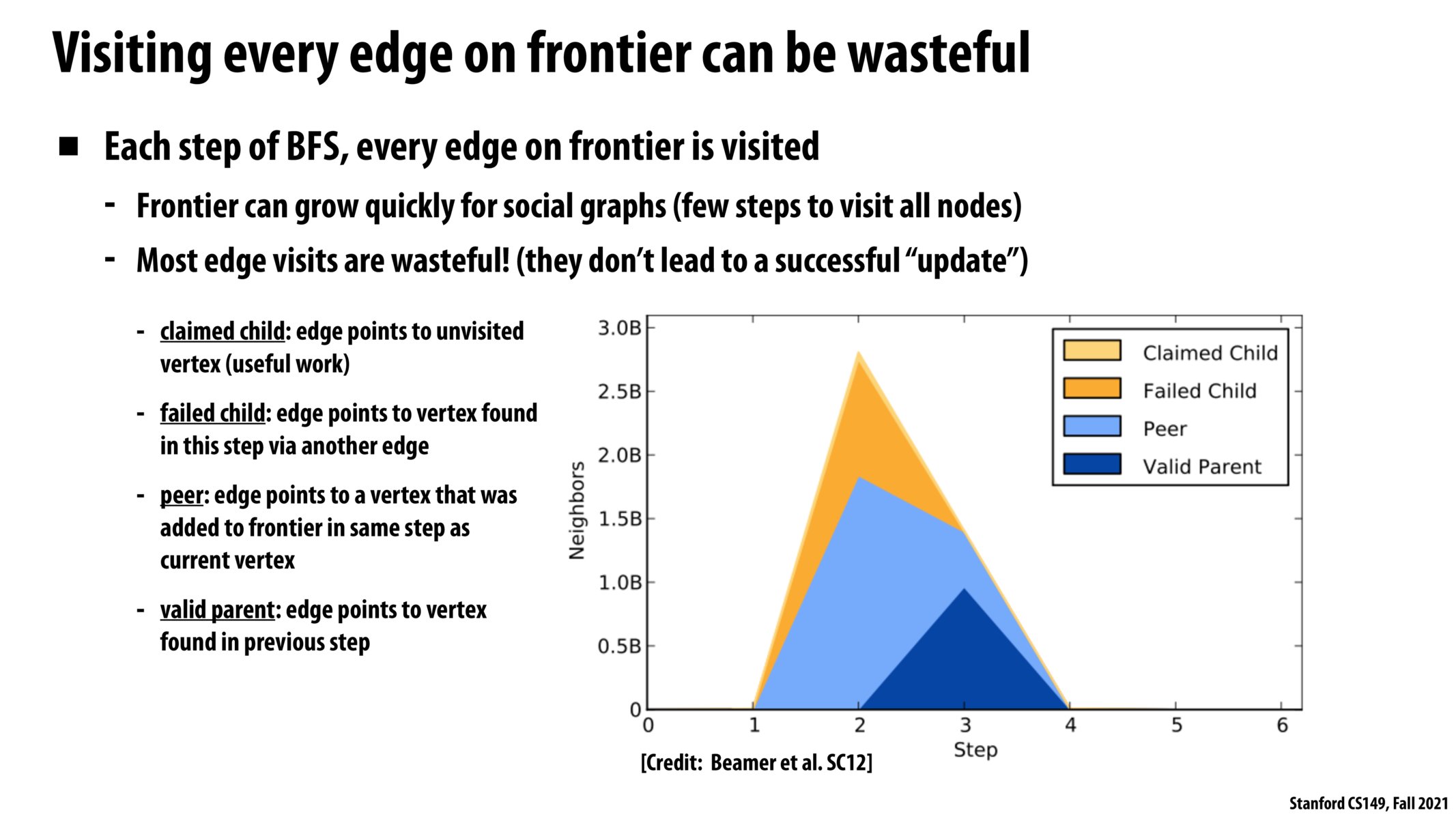


Based on my understanding, does that mean to speed up the program, we should try to also have a label for each edge, such that we could avoid duplicate visiting edges that point to nodes that have been visited? (Maybe through a visited edge set?) Though in this case we will still introduce the necessity to check against the set, and therefore will there be any gain in this case?

I think you're correct in determining that there would be no gain by labeling edges, since that would replace checking whether the destination node was visited. The bottom-up approach described in the next slide gets around this by running in parallel over all nodes. Any node that has already been visited will not attempt to traverse all its edges, saving some work.

i wonder how randomized algorithms (i.e. las vegas / monte carlo) for graph processing play out with parallel computing!
Please log in to leave a comment.
What's the way to avoid this? Create some sort of semi-relaxed synchronization whereby it's ok to visit some duplicates but if it's already existent in the shared set then skip that duplicate? Because if you have some mutex then everyone is going to get bottlenecked