

One thing that was mentioned in lecture but not written in this slide was that sorting was required before sharing or else this method of efficient access over shards doesn't work

Could someone explain the sliding between shards. I didn't fully grasp this concept from lecture?

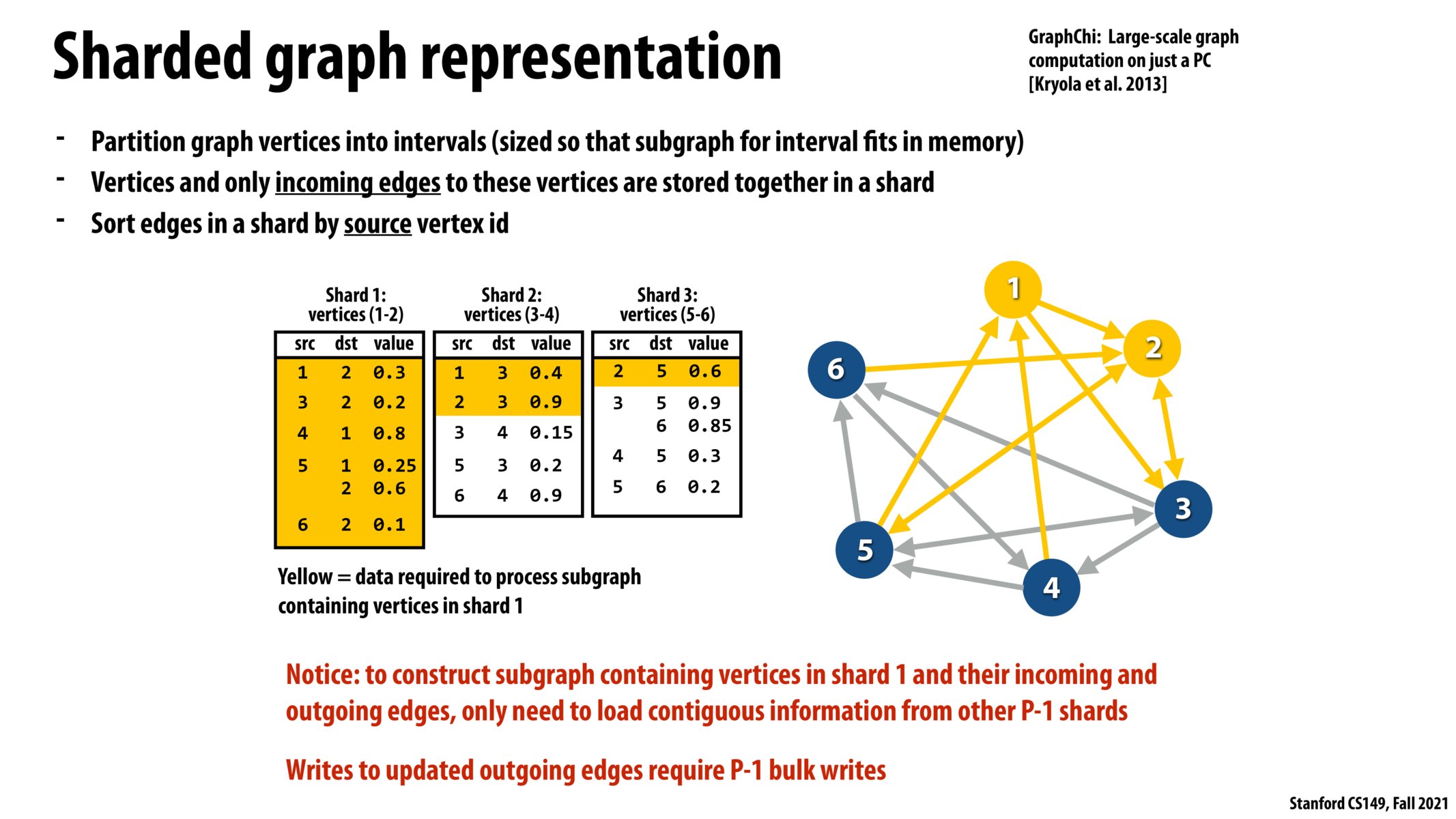
I am also slightly confused about these slides. I understand dividing up the vertices into shards but don't understand how the highlighter yellow sections work.

@evs @beste The picture can seem confusing at first, but if you stare at it long enough it starts to come together. In this example, we have three different "shards", where a shard is a subset of edges. Shard 1 consists of edges that point to vertices 1 and 2, shard 2 consists of edges that point to vertices 3 and 4, and shard 3 consists of edges that point to vertices 5 and 6. Furthermore, the edges in a shard are sorted by the source vertex (see how the src column in each shard is in ascending order).
Once you understand how the edges are distributed among shards, you can convince yourself that the edges highlighted in yellow are the ones that start and/or end with vertices 1 or 2. Since shard 1 corresponds to vertices 1 and 2, it makes sense that the whole shard 1 table will be highlighted. Compare this to the highlighted rows on the next 2 slides, and you will start to understand how the accesses to memory will always be contiguous (unless you require the whole shard).
The key idea is that the edges in a shard are sorted by source vertex. You can imagine splitting up a shard in chunks that correspond to the edges needed by other shards. Since the edges are sorted by source, we know these chunks will always be next to each other.

^continuing on tennis_player: The whole 'sliding down the shard' concept gets interrupted by the iteration in which you end up using the whole shard. You can imagine that each iteration you slide down the shard a bit, with the added layer on top that each iteration, the shard that gets used completely moves to the right. This 'using the whole shard' takes precedence over sliding down.

The whole idea of using graph representation is to make reading edges on a graph more cache efficient? I didn't quite understand why we need this sort of implementation.

This seems like a step backwards from fully separable graphs being processed independently, but I assume it can retain most of the performance gains?

@A bar cat I think that this implementation aims to handle temporal locality, so that each subgraph containing a specific vertex fits inside memory better.

This also took me a bit to parse, but wanted to emphasize that we need the shards to be sorted by src id so that finding outgoing edges for the current vertex of interest requires loading contiguous data other shards (besides the shard storing all its incoming edges), which is optimal for cache locality

I understand how this sharding makes for more efficient memory accesses, but how is the sharding determined? Are there multiple ways to shard the nodes? How do we ensure an even distribution of nodes amongst shards?
Please log in to leave a comment.
Extremely neat how we have DSL that pertain to graphs! Wondering if there are similar implementations for trees and other complex data structures? Trees come to mind as they are a very specific subset of graphs! If this exists, what are they an where are they used?