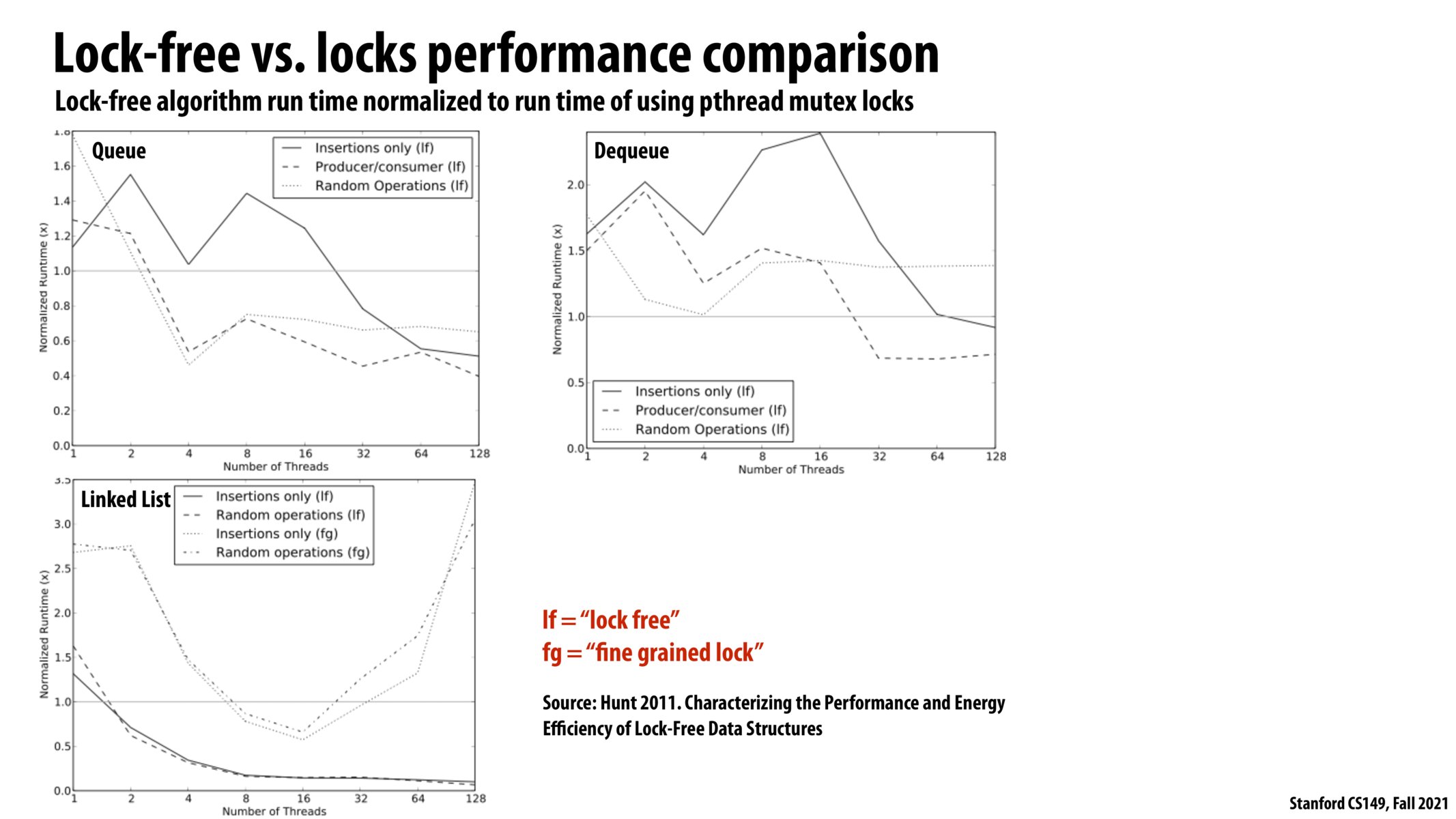


Lock-free implementations tend to perform better relative to lock implementations as the number of threads increase. This is because they don't have to worry about communication overhead.

I understand how that relative to increasing number of threads the lock-free linked list will outperform the fine-grained one. However, I find it interesting that the breaking point seems to be about 16 threads after which we'll start seeing sharply decreasing performance. It kinda reminds me of how a limited view of the data can be deceiving since if we cut-off the graph at 16 threads we might incorrectly conclude that the Fine grained implementation will eventually reach the lock-free one when in fact it will sharply decrease in performance after 16 threads.

I looked up the hardware they were using, which turned out to be a 8-core machine with 2-way hyperthreading (=16 execution contexts), so I started from there.
My first guess was actually preemption intolerance due to fair lock implementations, but I couldn't find a reference to the exact configuration of locks used in the paper.
What the paper did mention, however, was that pthreads, which they were using for the fine-grained mutexes (on some level), uses Linux futexes in their implementation which in turn use in-kernel spinlocks. They connected the contention on the futex spinlocks with the kernel putting threads to sleep (as pthread_mutex is typically a hybrid spin-sleep lock), which would cause performance to degrade due to sleep/wake overhead, thus explaining the degradation in performance as number of threads rose, which makes some sense in light of the turning point at 16 being equal to the number of ECs on the machine.
Or, at least, that's what I think they were saying; paper was found here if anyone's interested in further reading.
Please log in to leave a comment.
I found the comparison of efficiency between lock free and fine-grained lock implementation on linked list informative. In this case, lock free implementation is able to remain at fast runtime with increasing number of threads to hundreds while lock implementation is only able to remain relatively efficient at around 16 threads.
What causes the runtime to increase for lock implementation after 16 threads? Is it due to the thread contention on acquiring locks?