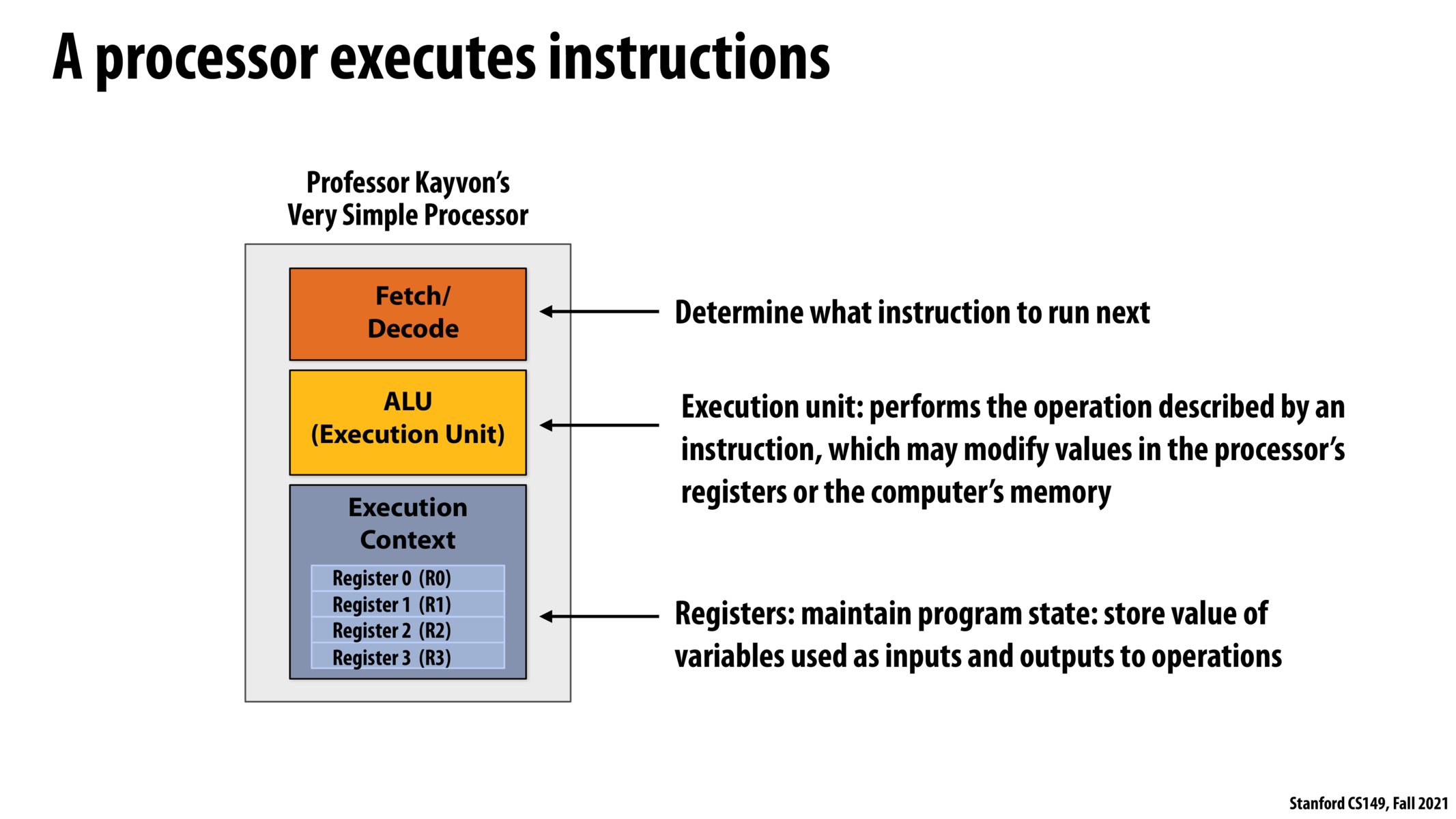


Like the slide notes, this is a (very) simplified model for modern processors. The mental model you have is not invalid, it is just even further simplified from what is shown on the slide, grouping the "fetch/decode" step with the "execution" step.
One of the reasons it is important to distinguish between these steps is that when you fetch an instruction, you go to memory (it could be a local instruction cache, or it could be all the way to disc). Fetching from memory introduces a potentially large latency and thinking about these issues is important when thinking about parallelism on a processor (e.g., if there is a delay in fetching the instruction, this is an opportunity to run another thread on the hardware while waiting for the instruction).
As far as I know, most operations on the ALU take 1 operation per clock cycle, and don't have these kinds of delays.
Please log in to leave a comment.
In previous classes, I am not used to thinking about the fetch and execution units as separate entities. Rather, I envisioned there being a single instruction pointer in the execution context, which contains the address of the instruction the processor can execute in a single step (after which the instruction pointer is normally incremented or otherwise updated in the case of a jump instruction).
How should I reconcile my previous mental picture with this layout -- is the separation of the Fetch and ALU units just breaking down two operations I had previously abstracted into a single concept? Any other advice to help update my understanding?