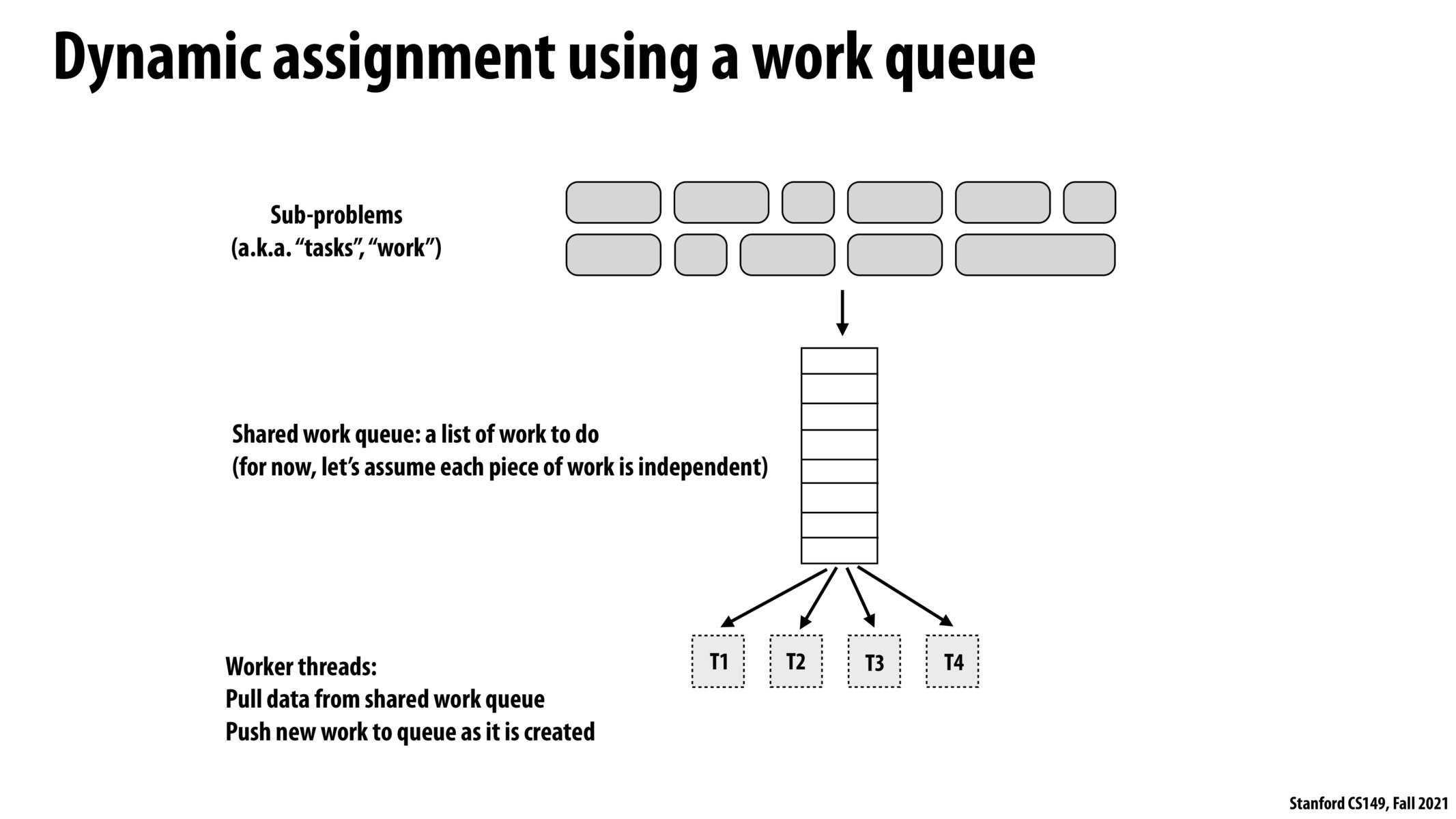

@vgupta22. To clarify in PA1, prog 1, there was no SIMD execution involved. In the example here, there is a work queue for distributing tasks (work) to worker threads. The only inter-thread communication is the synchronization on the shared work queue.

On PA 1 me and my partner were confused on why increasing beyond the 8 hardware threads kept giving us more and more speedup. If I understand it correctly I believe this slide answers that question. Having more than 8 tasks prevented threads from becoming idle by distributing the workload more evenly.

I was wondering how using random numbers for dynamic assignment will impact performance. I will try that on PA2 with my partner

@ckk My partner and I are trying that too. I think there are a lot of domains where the tasks have predictably increasing or decreasing compute time, which could make assigning them to threads in a naive order potentially pathological. One can imagine the Mandelbrot computation inducing this.

Is there any case where static assignment is more efficient? It seems to me that we only use static assignment because of its ease of implementation.

@ia374765 When the overload resulting from a complex dynamic assignment implementation is too much perhaps?
Please log in to leave a comment.
Why do we need to use inter-task communication in this case whereas in prog1 and prog3 we just split up tasks and had them run using SIMD and no communication?