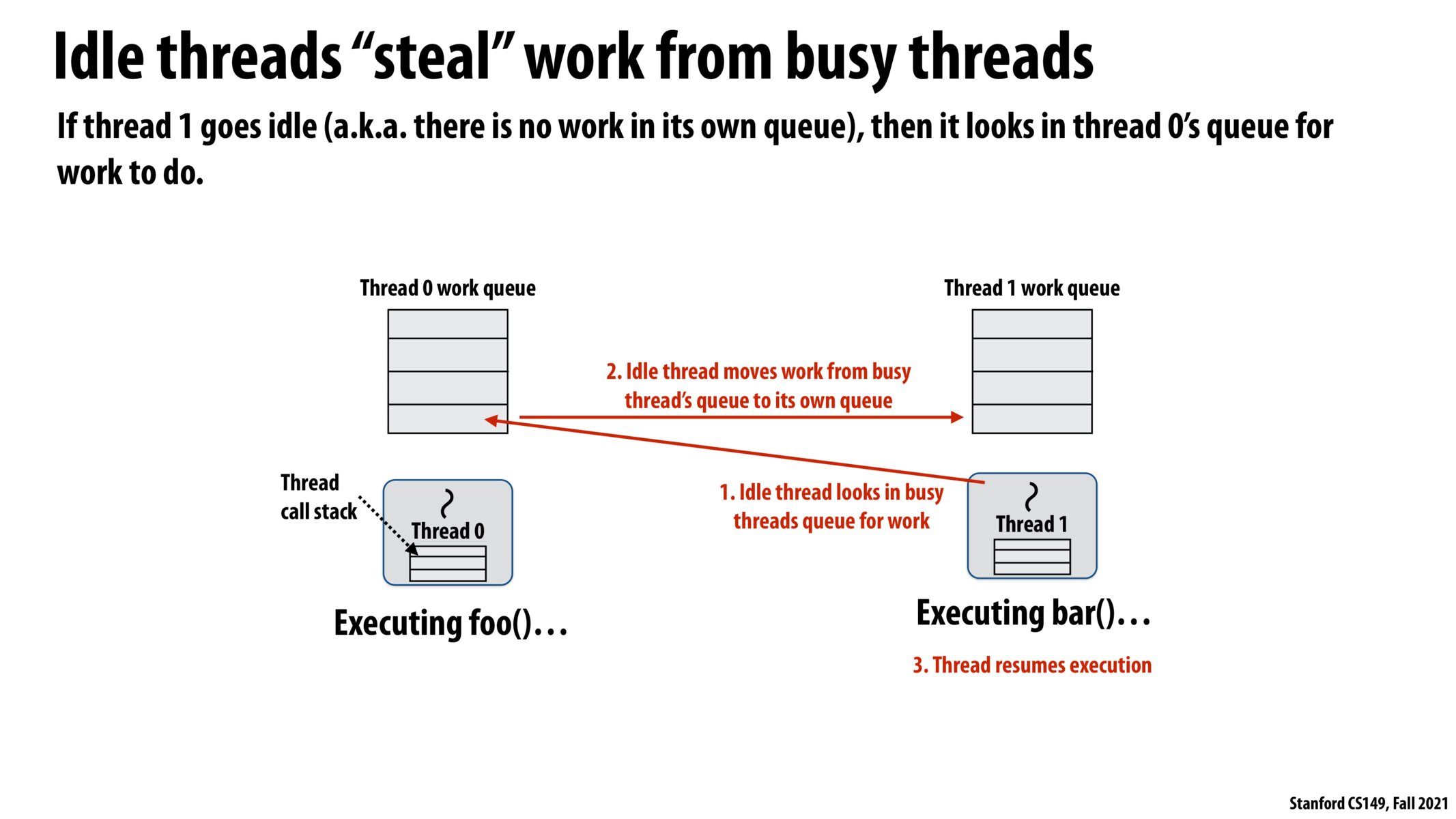


@brianamb I think the reason why it's better to have individual queues rather than a shared queue is because of the reason you pointed out - with a shared queue there's a lot of synchronization overhead. Imagine you have some huge processor that can run like 100 threads, then with a shared queue + locks you would be serializing the ability for workers to get new tasks. In a somewhat extreme case, if the tasks were very short, you might not be able to even assign all 100 threads a task before the 1st thread finishes and tries again to acquire the lock on the shared queue. On the other hand, with individual work queues, once these queues get filled up, each thread can chug through its work with much less synchronization overhead (maybe we still need to synchronize with another thread when it wants to steal work).

How do threads keep track on any dependencies in the work that they steal? Couldn't there be an issue if running bar() relies on some state-change caused by foo()?

I had initially been confused on the use of "thread" throughout the lecture - I believe "thread" isn't referring to the same ones we see in 110 (like p thread - the ones that require separate execution contexts). they refer to just another stream of programming instructions that can be interleaved in a specific way as specified by cilk.
Please log in to leave a comment.
Why not have a shared queue instead? This seems to be exactly the same except not having to do as many locks. Is it because we are constantly fighting for the lock in the shared queue, meanwhile here we lock rarely to get big chunks of work?