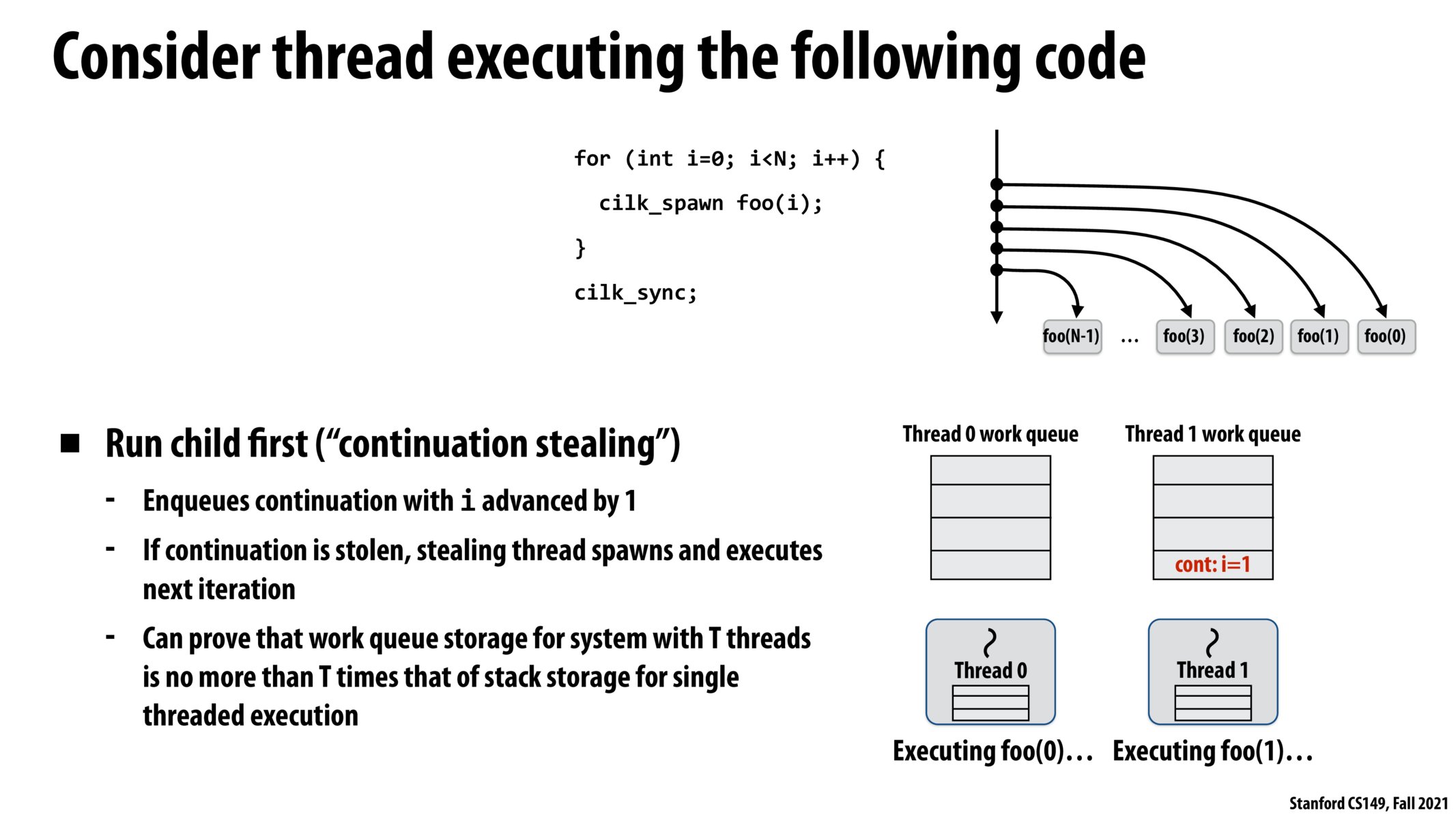


The slide says "Enqueues continuation with i advanced by 1", then should the thread 1 work queue contain count: i=2 instead of count: i=1?
If I understand correctly, the savings we get from each thread having its own work queue is not that each thread can add to its own work queue with no synchronization. Otherwise, there would still be synchronization issues with threads that are not Thread A trying to check Thread A's work queue at the same time that Thread A is trying to enqueue work. That leads me to believe there is a per-thread work queue lock. Is that the typical implementation?
I also believe that if the actual work is sufficiently large, it will take much longer than the synchronization costs, so the overall speedup provided by trying to speed up this operation is minimal. Thus, we go for a simple solution with relatively low synchronization costs. Is this the right way of thinking about this?

So we don't want to fill up the stack space by running the child first since the child will keep spawning a ton of tasks?
Please log in to leave a comment.
I was confused as to why each thread has its own work queue: it seemed more natural that each thread could enqueue and dequeue work atomically to a shared work queue. However, it now makes sense that each thread having its own copy reduces synchronization costs.