It seems like to understand these unpredictable runtimes statistically, it might be useful to understand the rough distribution (or asymptotics) of the maximum of n random variables of various kinds, as splitting work roughly evenly, we have to deal with the maximum runtime across n tasks.
I'd guess pretty common/reasonable models might be geometric, exponential, binomial, and Gaussian RVs. And the expected "extra time" (from taking the max over n variables instead of one variable) scales as roughly as log(n), or sqrt(log(n)). This seems like a pretty glowing statistical endorsement of using parallelism, as that's a pretty slow scaling rate, but I'd guess real-world tasks have fatter tails than these RVs. Some interesting analysis to be done there!
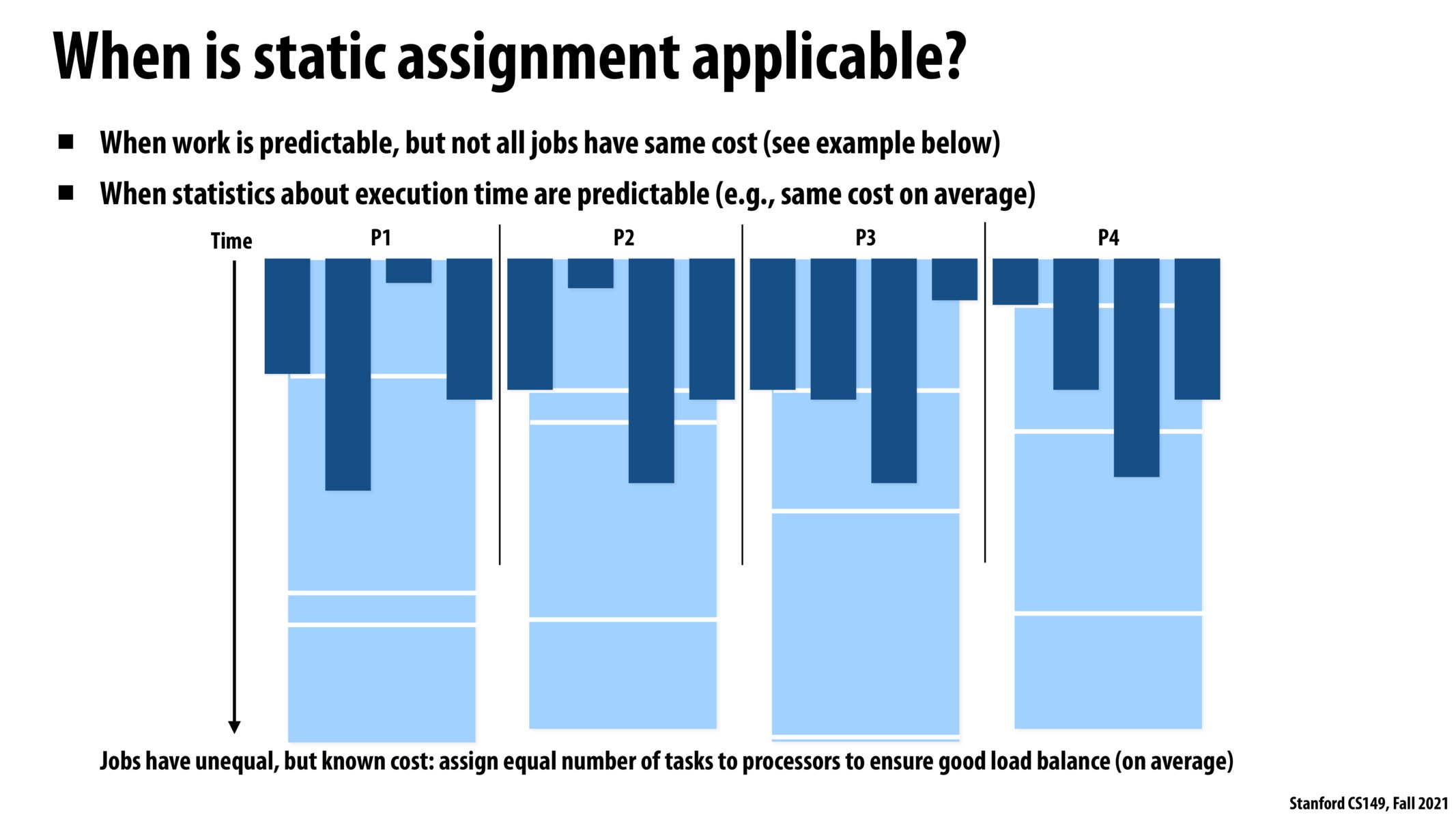

It seems like to understand these unpredictable runtimes statistically, it might be useful to understand the rough distribution (or asymptotics) of the maximum of n random variables of various kinds, as splitting work roughly evenly, we have to deal with the maximum runtime across n tasks.
I'd guess pretty common/reasonable models might be geometric, exponential, binomial, and Gaussian RVs. And the expected "extra time" (from taking the max over n variables instead of one variable) scales as roughly as log(n), or sqrt(log(n)). This seems like a pretty glowing statistical endorsement of using parallelism, as that's a pretty slow scaling rate, but I'd guess real-world tasks have fatter tails than these RVs. Some interesting analysis to be done there!