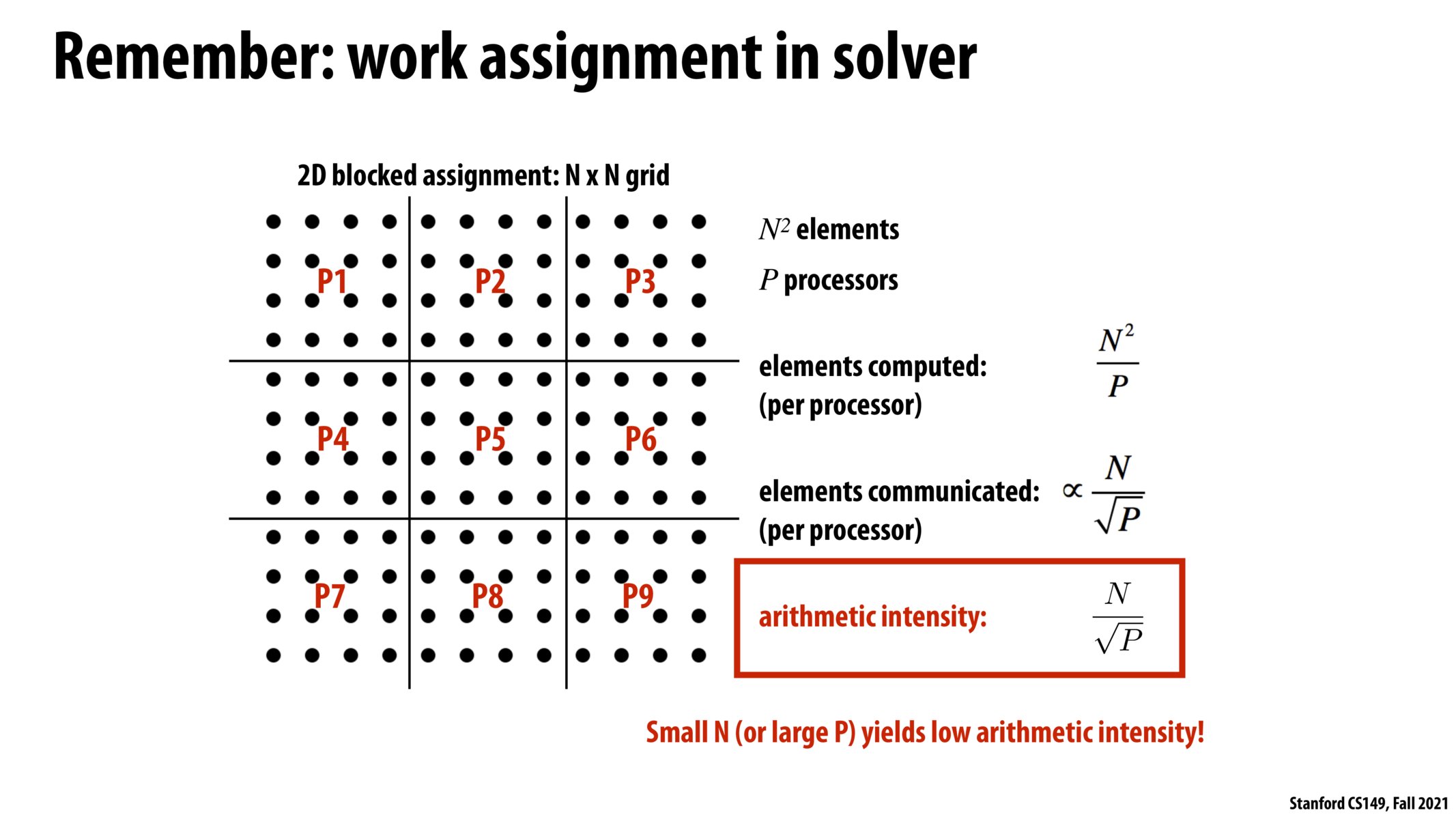


Review note: since there are sqrt(P) rows/columns of processors and N rows of elements, the number of elements which must be communicated is proportional to N/sqrt(P)

I think the concept of changing how the algorithm is processed is interesting, basically kind of manipulating the work so that it can operate in a way that it changes the arithmetic intensity to our favor given the hardware. However, this approach seems like it works only if the order of processing can actually be changed or not. In this case, the ordering is parallelizable, but it seemed like there needed to be some strong insight to realize that the ratio of area to perimeter was important. Is there a guideline of tactics that allow for more generalizable ways to think about ways to manipulate our implementation beyond something like this problem? Or is it really done on a case by case basis and is hard to actually scale this to a generalizable way.
Please log in to leave a comment.
Great way of using area to perimeter ratio as a way to think about arithmetic intensity. I think I am beginning to understand where this is heading. This pattern of reducing area to perimeter is why GPU architectures have some sort of blocks, dimensions in addition to threads as a way to partition data. So, it must be that the parallelization of problems must have this objective of maximizing area to perimeter as a frequent enough occurrence that the code libraries like CUDA have built this structure into the design itself. Nice.