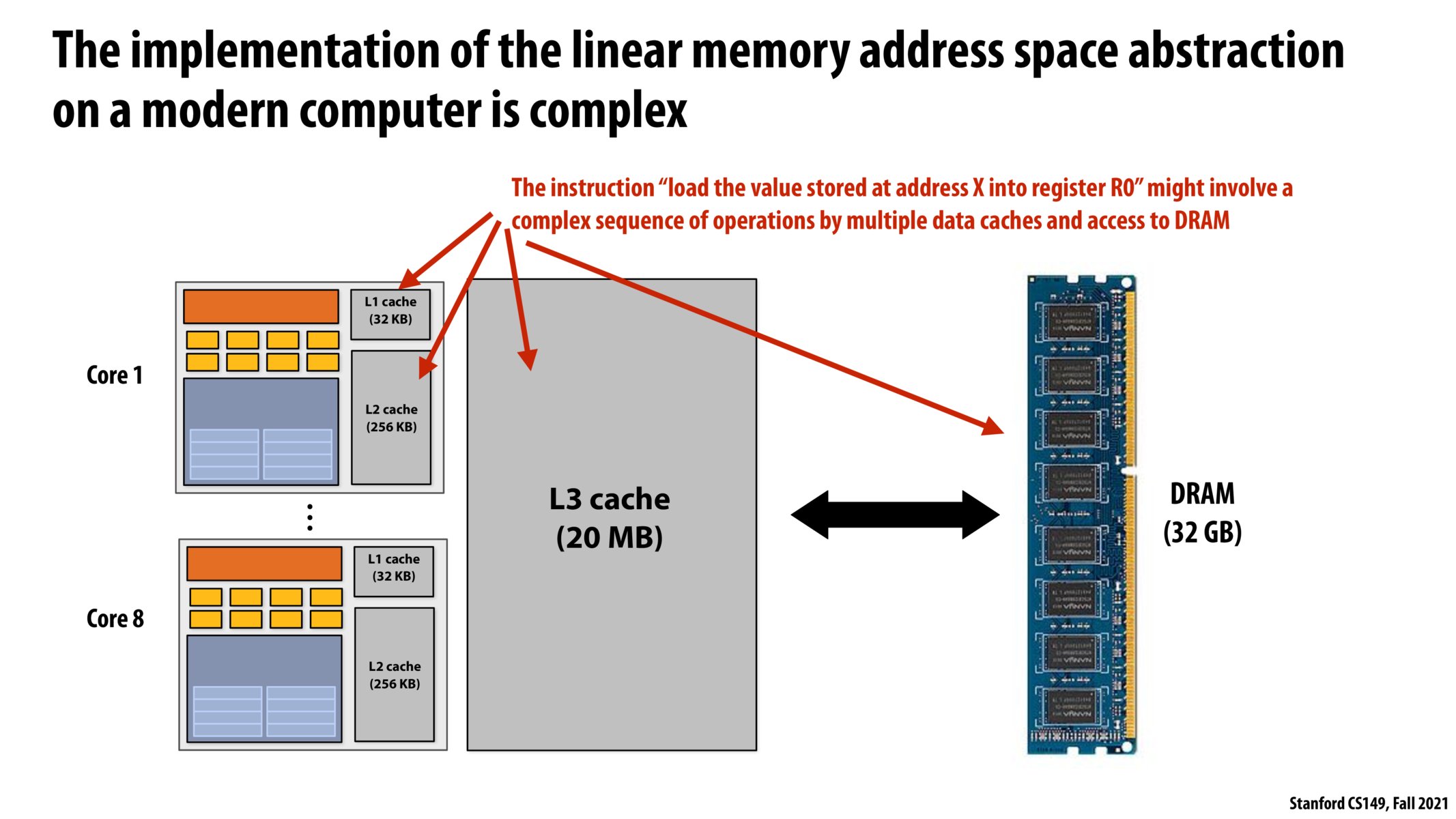


I prefer thinking of this in the following way. The fact that a program has linear memory address space is merely an abstraction - this enables a programmer to think that every process gets a contiguous chunk of memory equal in size to the size of that process's memory image. This abstraction is very different from the real implementation - multiple levels of cache, each holding data fetched from the memory spaces of multiple simultaneously running processes, with no real contiguity of memory addresses to speak of.
As for the access times, the answer is simple. Looking up the data at a particular memory address takes much longer the larger the size of the memory is. This essentially gives us the following order:
Size, as well as Latency : L1 < L2 < L3 < RAM < Storage

Is there a fundamental reason why we can't make the L1 cache on processors bigger? Will increasing it size reduce the speed at which data can be fetched from it?

So what hardware differences exist to explain the difference in latency between L1/2/3 caches? Is the relationship between size and latency a correlation or causation?

When there is a hardware tradeoff between cache size and cache lookup time, it makes sense to have multiple available options at different points along the tradeoff, so we can utilize the most appropriate level of cache depending on the application's needs. I'm curious how we actually ended up choosing the number 3; in principle, it feels like there could easily be more levels of caches. Perhaps it is the case that at 4 caches we start getting diminishing returns from the extra cost of adding more caches to the hardware; if so, how would we go about figuring this out? If it's purely empirical, is it possible that the tradeoff has changed over time?
FWIW, it looks like a couple of Intel CPUs in 2013-14 actually did have L4 caches, like the Intel Haswell and Broadwell chips. Also, we can think about the CPU registers kind of like an L0 cache, since it's a very small amount of memory with very low latency.

Is there an easy way to continue this abstraction into permanent storage like a hard drive?

Is there a reason only 3 levels of caches exist? Why do we not incorporate L4, L5, etc?
Please log in to leave a comment.
So is the idea here that L1, L2, and L3 cache are an abstraction implemented over DRAM. and if so then why does access to L3 cache take longer than L1 if everything is on DRAM any ways.