

You're right, in many use cases, cores can be heterogeneous. While more powerful cores can be used for tasks that demand performance, low-power cores can be preferred when efficiency is needed. For example, high-end Qualcomm SoCs typically have a combination of Cortex X, Cortex A7x and Cortex A5x cores.

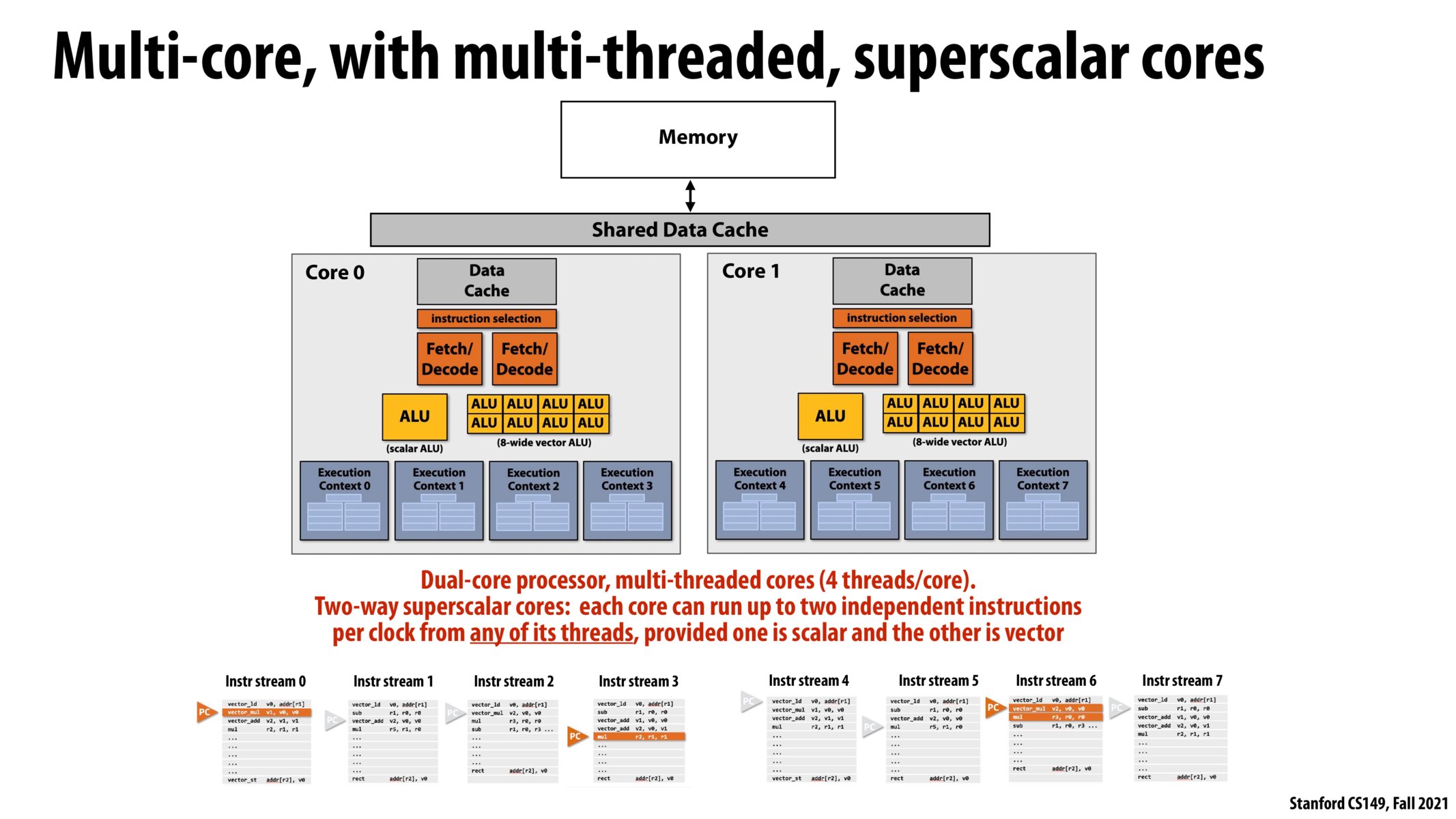
To rephrase this slide: - single core superscalar = able to run multiple instructions at the same time - single core multi-threading = running one instruction at any given time, choosing from multiple streams of instructions - multi-core superscalar = able to run multiple instructions at the same time, on each core - multi-core multithreading = have multiple execution contexts and able to run instructions from any of the hardware threads, on each core
- a modern processor (like the one above) is multi-core, superscalar, AND multithreaded.

I thought this section of the lecture with Kayvon's explanations over these slides was very succinct. Simply put, there are two ways we can optimize our performance with these CPU architectures. 1. We can use the abstractions of threads to hide latency by interleaving the most optimal combinations of instructions onto the ALUs (to optimize for utilization).2. We can also use the concept of multiscalar operations to run more than one instruction on a core and we can have multiple cores running at the same time to multiply how many instructions we can run. These two strategies can help us increase our compute power if we do not get bottlenecked by a bad ratio of high-latency operations to fast computations.

I also liked Kaybon's explanation of the difference between 4 threads interleaved on one core versus 4 cores with one thread each. In the former case, the 4 threads are sharing the same resources, and we haven't increased the ability to do more math at any time (peak capability) but we have increased utilization, because the threads can figure out what to run at each clock if one of them is stalled. With 4 cores, we replicate the execution context, the execution resources, and the data caches that number of times, so we've added more resources which increase the peak capability.
Kayvon* sorry for the misspelling!
Please log in to leave a comment.
Are cores usually the same with respect to their proportion of scalar/SIMD ALUs and the number of execution contexts? I imagine that this is the case in GPUs, but are there cases where you would want the cores to be more heterogeneous?