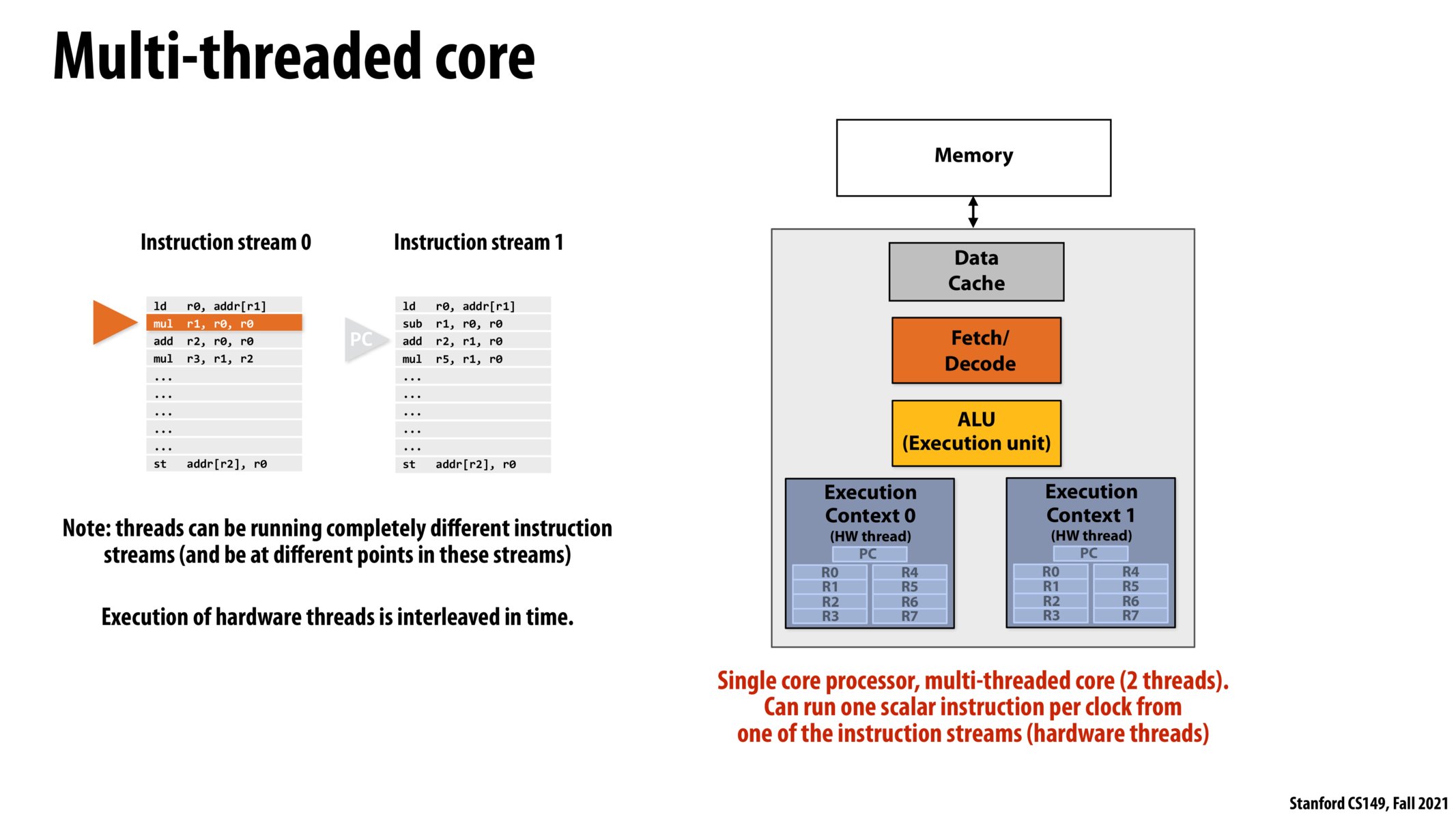


Correct. The reason for this is that there's only one execution unit, so the two threads have to take turns seeing which one gets to execute the next instruction in its instruction stream.
Hardware threads (from what I've seen in the class so far) seem to be useful mostly when there is latency in certain operations that hinder full utilization of the execution unit. In other words, when there's a part of the program that isn't using the ALU due to waiting on something (be it main memory or a disk access), other threads can try to make forward progress on their instruction stream.

I think for a while I did not fully see the difference between Multi-Threaded and Superscalar but I think after going to a few office hours and reviewing the slides a few times over it finally makes sense. A multi-threaded core only has the ability to run a single thread at a time even though it may have multiple execution contexts while a superscalar has the ability to run two separate instructions from the same instruction stream at a time. Also, I suppose one of the other major differences is that the multi-threaded core can have 2 different instruction streams stored on it while, as I mentioned before, a superscalar only has room for 1.

This is where the OS does scheduling decisions by putting all the threads on various priority like ready queues, wait queues etc. Take CS140 to actually program this out.
Here, the CPU would make the HW thread scheduling decisions. The difference is the cost of HW context switch is insignificant compared to the significant Software context switching (1000s of cycles?)

Multi-threading increases utilization of the ALUs. However, multi-threading is not true parallelism in the sense that, with superscalar or multi-core, only one instruction is running at a given time
Please log in to leave a comment.
To check my understanding, two threads with high arithmetic intensity will not benefit much from the architecture shown here. Does that sound correct?