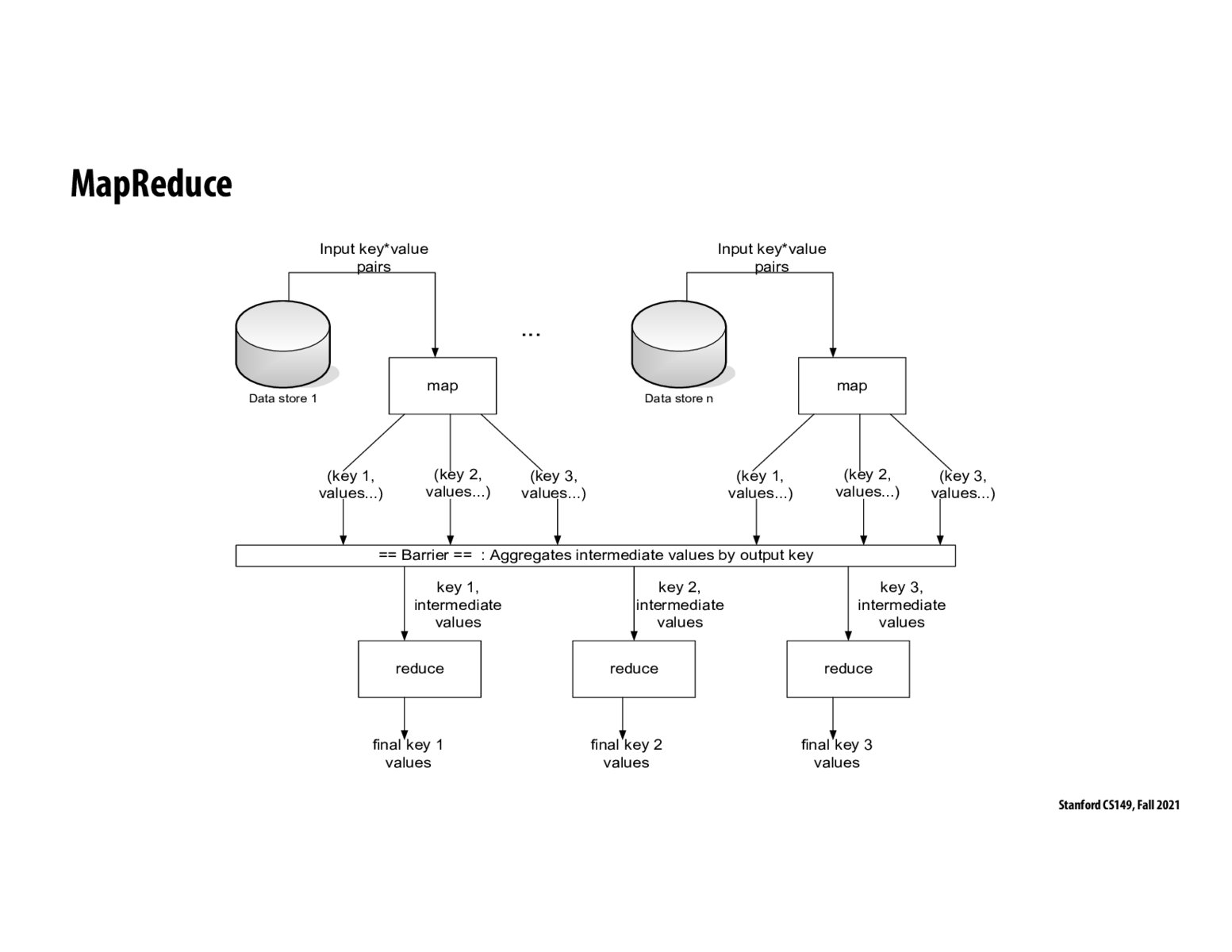


This slide explains on a high level how MapReduce works. Each mapper outputs intermediate values for each key. The barrier ensures that all mappers have completed. There is an implicit groupBy operation on the keys so that each key is followed by a list of intermediate values from all the mappers. The reducer then work on this list to create final values for each key.

Is the MapReduce programming model constrained to only data that is organized as key-value pairs? In other words, does data that needs to be processed using MapReduce requireed to be organizable in some way as key-value pairs?

say we have (key 1, [v1, v2, v3, v4]), (key 2, [v1, v2, v3, v4]). First we split them into 2 groups, the first one has (key 1, [v1, v3]) and (key 2, [v1, v2]), the second group has (key 1, [v2, v4]), (key 2, [v3, v4]). Each group then runs the map function and become (key 1, [m1, m3]), (key 2, [m1, m2]); (key 1, [m2, m4]), (key 2, [m3, m4]). Then we aggregate them by keys -> reducer 1 will have (key 1, [m1, m2, m3, m4]), and reducer 2 will have (key 2, [m1, m2, m3, m4])

I'm rather confused.. Why wouldn't you just have the first group be (key1, [v1, v2]), (key1, [v3, v4]), and have the second group be (key2, [v1, v2]), (key2, [v3, v4]), and then we can eliminate the need for keys? I guess this is also to restate albystein's question about the significance of key-value pair inputs.

What are some practical use cases for MapReduce? I've heard of it multiple times here and there, but am not quite sure what its practicality is.

What are some of the shortcomings of MapReduce?

@lee I looked up some of the issues because i was curious; lack of inter-process communication, and the inabilty to handle streaming data seems to be some common issues.
Please log in to leave a comment.
Sometimes the reducer does no computation but just prints out the sorted output like in a word count type mad-reduce task. In this case would the way the load is distributed across mappers and reducers be different?