I dont understand why page rank in this case must load from disk each iteration. Wouldn't you have the output from the last iteration? Why do you need to write it back? Is it because that output is too large to store in working memory, and you would need to write it back first?
Also, I thought that distributed filesystems were meant for files that weren't updated in place a lot. If you're constantly writing back a new value for the node's page rank, doesn't that violate this assumption?
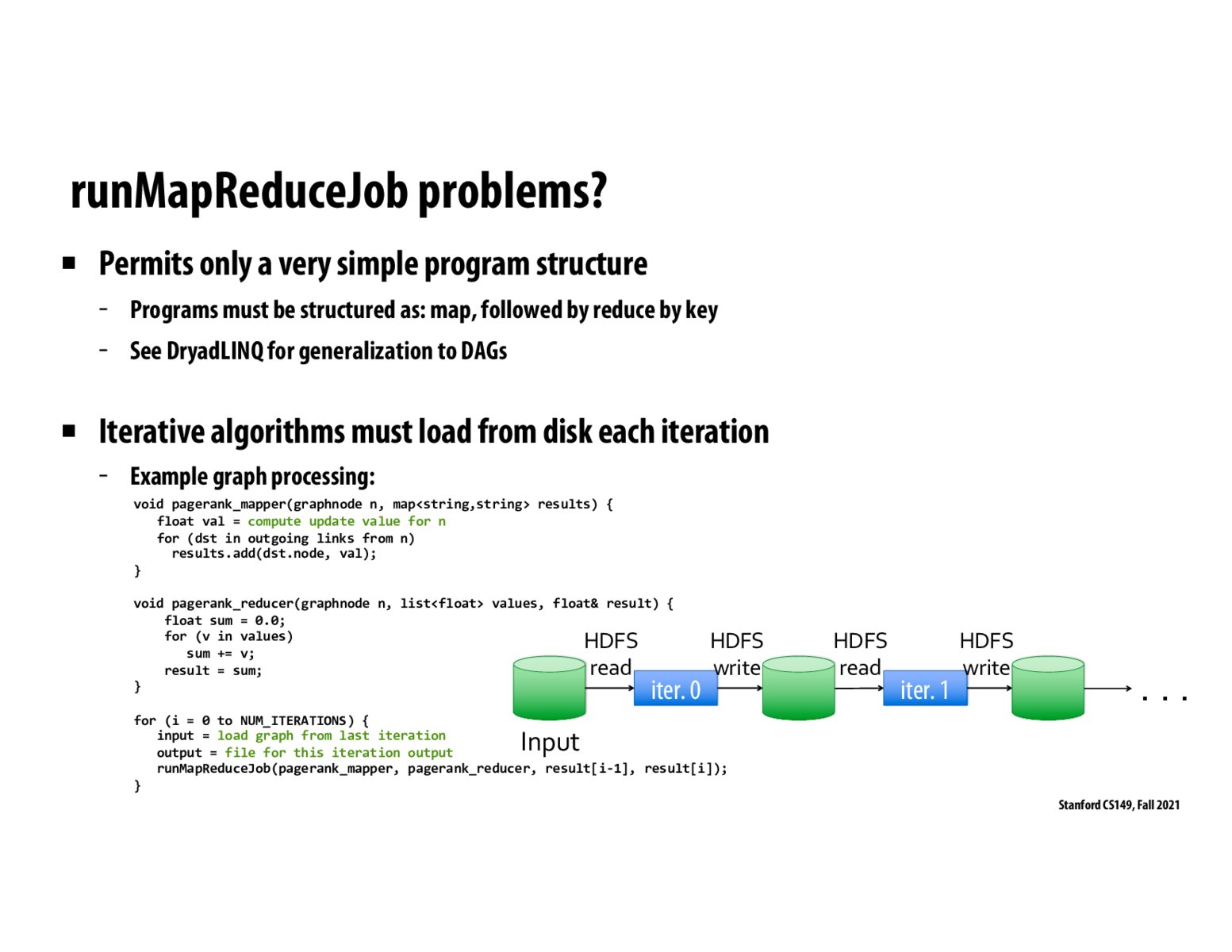

I dont understand why page rank in this case must load from disk each iteration. Wouldn't you have the output from the last iteration? Why do you need to write it back? Is it because that output is too large to store in working memory, and you would need to write it back first? Also, I thought that distributed filesystems were meant for files that weren't updated in place a lot. If you're constantly writing back a new value for the node's page rank, doesn't that violate this assumption?