Back to Lecture Thumbnails

ghostcow

lindenli
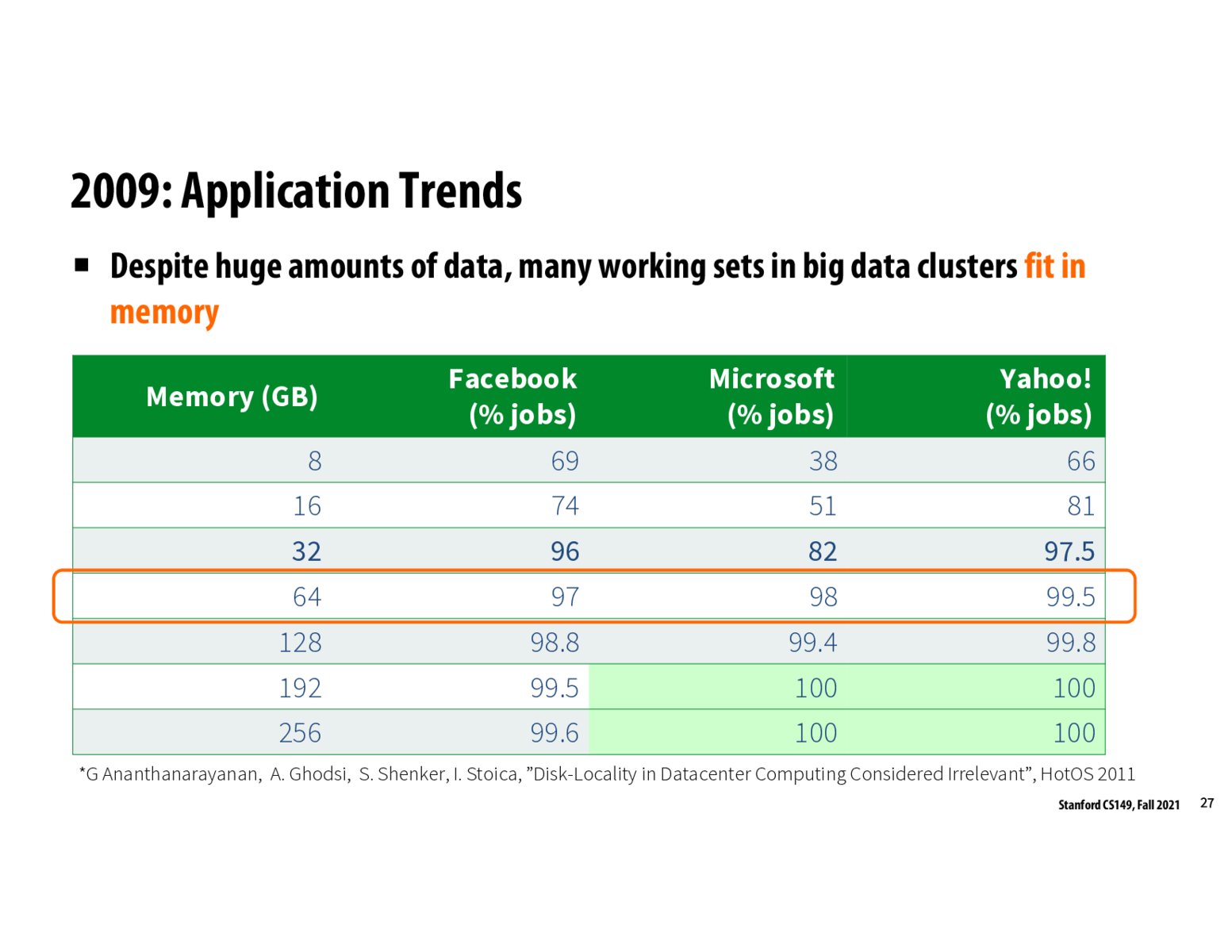
This slide was quite compelling, but also confusing to me. I'd imagine that a company on the scale of Facebook has huge amounts of data that they're mining - how could we realistically fit this in working memory?

gmudel
@lindenli I think it actually just does fit in memory. Putting real numbers (if only approximate) may help. Say there are 1 billion (10^9) FB users. If we have some features, (say 16 bytes) for each users, then our dataset is 16 * 10^9 bytes, or ~16GB in size, which is exactly how much RAM my 2016 Macbook Pro has
Please log in to leave a comment.
This slide seems to be the primary reason behind the motivation (and success) of Spark. It turns out that most working (intermediate) sets of big data clusters fit in memory, which means that one can create in-memory representations of data and avoid repeatedly persisting intermediate outputs to disk, which can result in massive practical slowdowns. Spark's use of RDDs (fully in-memory, with operations fused as necessary and persisting only performed when necessary) achieves this.