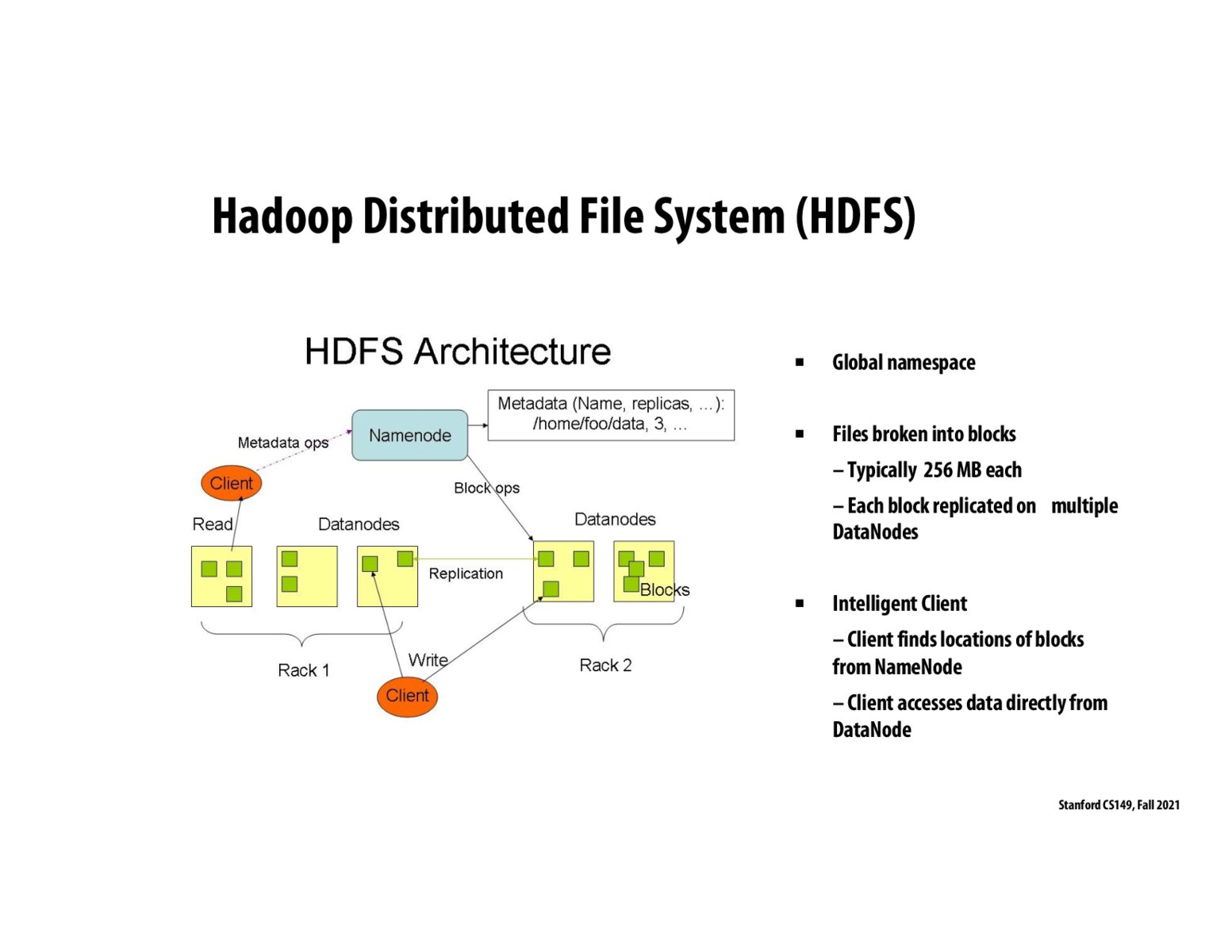


Suppose the Client wants to write. It will retrieve the metadata from the Namenode, which will tell the Client where all the replicas are, after which the client can write to them.

There are 2 cases: (1) If the client wants to read data, it finds the location of it want to read from the NameNode (containing metadata), and reads from the DataNode. (2) If the client wants to write, it will write to all replicas of block on multiple DataNodes.

Fun fact: HDFS was first designed and implemented based on the GFS (Google File System) paper conceptual model.

I too find this diagram a bit confusing. Doesn't the client also need to talk to the namenode before it write? It should write to all replicas, so it should get where all replicas are before writing, right? Or does it only write to one copy, and the file system will automatically replicate the write to all replicas?
Please log in to leave a comment.
I found this diagram a little confusing to follow during lecture. Where does this process start? Clients pictured the same or different clients? I suppose now that I am looking at it it appears that they are different clients performing different operations. Another question I have though is one of the clients is writing to the same rack that another client is reading from. If one client writes to the same data node another client is reading from, couldn't this become problematic? It seems analogous to the issue in multithreading where we have shared state among the threads and we need to ensure only one can access the data at a time. One other observation I have is that while I understand it is necessary to store copies of information across nodes incase of a failure, this seems a very(space) costly way of ensuring the preservation of our data.