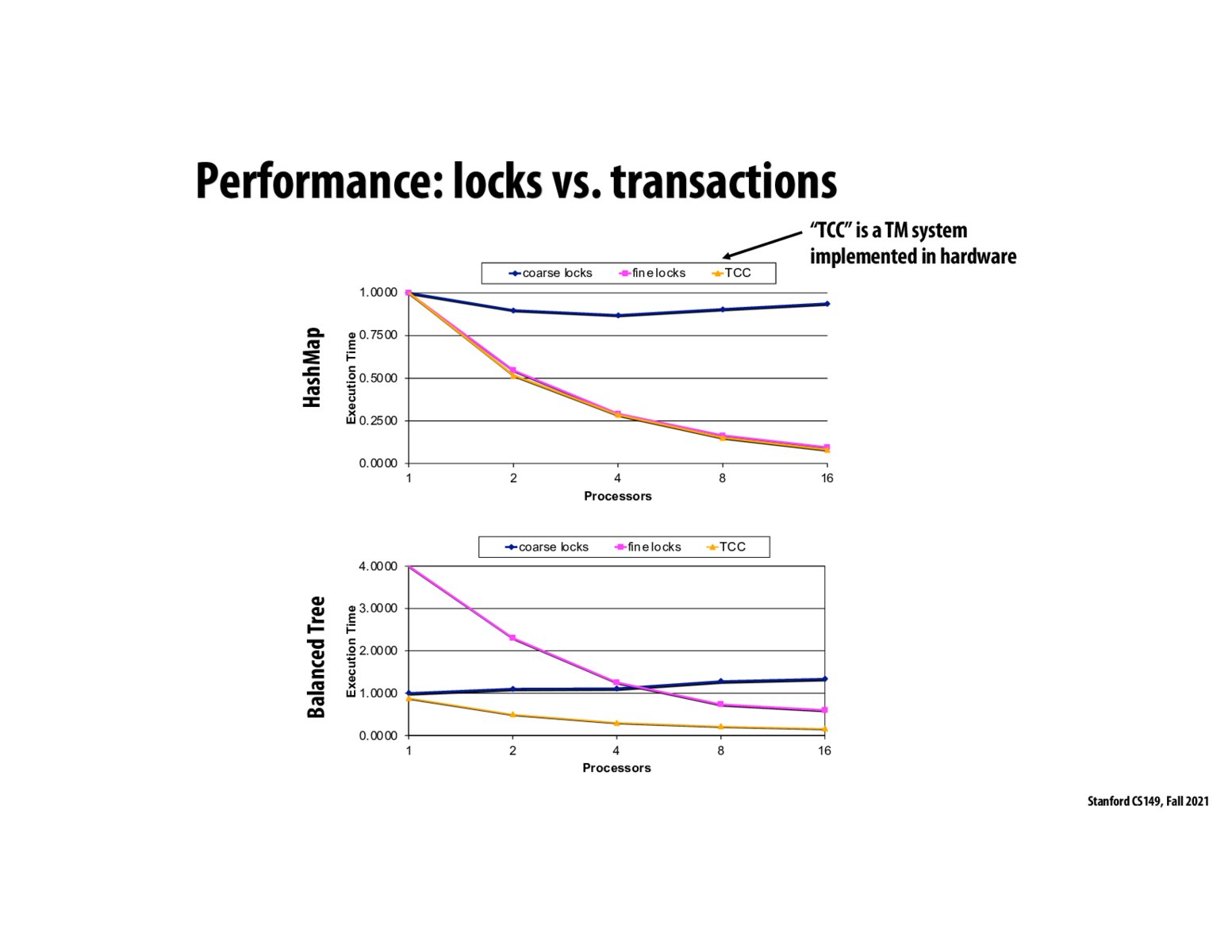


How heavy is the overhead of figuring out the conflicts between transactions? It seems they are small given how TM does strictly better in these graphs.

I thought it was interesting that during lecture, the main takeaway was that in the HashMap scenario, TCC was shown to be as good as finelocks, but I was expecting the takeaway to be that TCC was NOT better than finelocks, especially since the opposite was what I was naively expecting to be the case. Why exactly is it that TCC is not better than the finelocks in this scenario? Is finelocking the buckets the best we can do and how the TCC implements it under the hood as well and as a result finelocking becomes a lower bound of performance for TCC?

@derrick I wonder if we see an improvement from TCC as we decrease the size of our buckets since we must rely on linked lists to iterate the elements in a bucket.
Please log in to leave a comment.
To summarize, TM has the ability to leverage more processor to reduce execution time in the HashMap case. Unlike find-grained locking, It can also avoid introducing extra overhead in the balanced-tree case.