Back to Lecture Thumbnails

gmudel

amohamdy
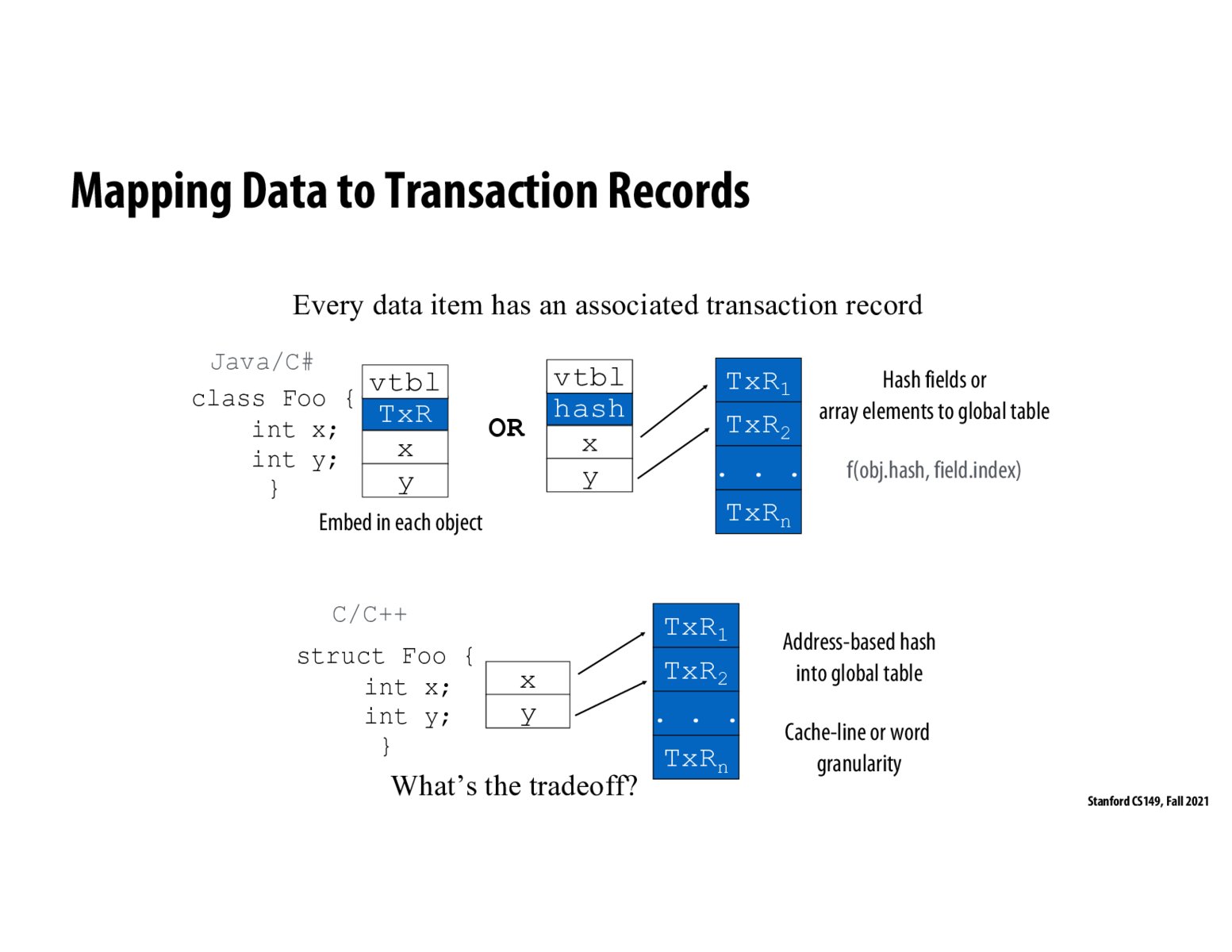
The tradeoff here is that if we store transaction records on the object level, we might get cases where two processors that are acting on different fields of the same object have to pointlessly check and potentially stall or abort each other since they're not aware that they'd be acting on different parts of the data and can act independently. The cost is obviously a memory overhead that we incur to save transaction records for each of the fields instead of one per object.
Please log in to leave a comment.
Note that this slide is making two points (in my opinion): 1. We can set how finely-grained our transaction records are. Finer-grained records incur more overhead, but result in fewer conflicts (think false sharing from the cache lectures) 2. Different languages might use different constructs for transaction tracking. Java and C# are obj-oriented, so it makes sense to store transactions at the struct or struct-field level. C/C++, however, place more emphasis on memory internals and thus we track transactions w.r.t. cache lines or words.