

See Amdahl's law. Performance increase is not directly tied to parallelism because it depends on the specific algorithm / program and how much you can parallelize it. I'm not being very precise here, but the idea is what we saw in lecture: (1) dependencies in your program on previous computation act as a bottleneck leading to some sequential operations that cannot be parallelized (this is Amdahl's law) and (2) increasing parallelism also increases communication overhead leading to diminishing returns (note you can have negative returns where it's beneficial to reduce parallelism in certain situations).
Ah, so would that mean that something like a geekbench score is not really a great indicator of performance because its descriptiveness depends on the set of operations being used to take the measurement?

There are different metrics for performance (latency, throughput, etc); if a program runs 2x faster with 10x cost, it depends on the metrics to measure to reason about if it's a net win overall.
Also, the bottleneck might be CPU (compute), memory bandwidth, IO, etc. If bottleneck is not around compute, increasing parallelism usually doesn't improve metrics much (yet still incur communication overhead as previous reply pointed out).

I am confused by the claim that parallel processing wasn't important when we can benefit from hardware improvement. For performance critical code, my understanding is that we should still parallelize it whenever possible and when next generation CPU is available, that just means the parallelized code will run faster.

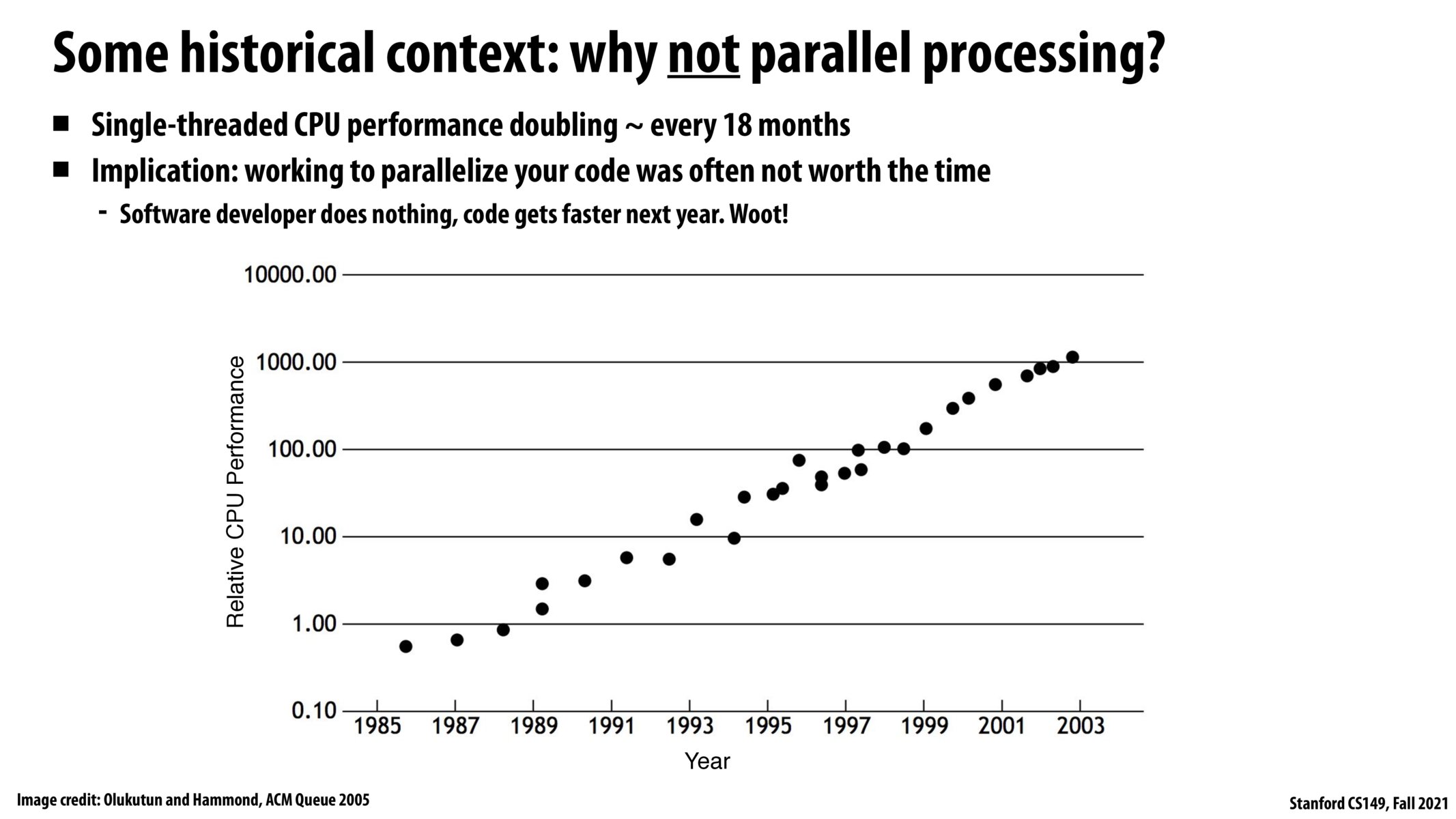
I believe the comment wasn't that parallel processing wasn't important, but rather that programmers could afford not to do it because hardware was getting reliably faster every year.

Yes, I agree with @gsamp. I believe we briefly discussed how quickly CPU performance was increasing, essentially making parallel programming 'useless' as it was enough to simply use new technology for better performance (see Moore's Law on transistors). However, it seems we're approaching the end of Moore's law and other methods (i.e. parallel computing) must be used to increase performance.

I'm really excited to learn about parallelism in this class. However this slide led me to think of the limits to parallelism in comparison to CPU performance doubling. This lecture demonstrated how powerful parallel programming can be, but it seems like parallel programming won't be able to fully replace the benefits of Moore's law. Moores law universally sped up computers, where as parallel programming will need to be implemented on a more individual basis for actions/progams.

@terribilis I'm also interested to hear about the focus on efforts between trying to improve the capabilities of parallelism vs the capabilities of a single CPU. I like your point about parallel programming possibly being customized for more specific tasks vs Moore's law CPU improvements being a more general performance improvement. I'm interested to see what most people think has more potential to have a greater impact.

This slide shows how CPU performance improved in the previous decades solely by hardware progress, with no improvement in software. This is because the number of transistors that can be placed within a given amount of area kept increasing(Moore's Law). How does this help improve CPU performance? When transistors become smaller, they become faster. They can run on higher clock frequencies. Thus, HW improvement over the years in the past helped in improving CPU performance. But now Moore's law has begun to saturate. So, I believe parallelism should now play a lot more role to improve performance.

This new era of computing definitely shifts more responsibility onto the programmer to ensure that their code is written in a way that can be dumbly run by the processors in a parallel way without fancy optimizations. I'm wondering how much of this gap can be made up by writing in more abstract/high level languages or compilers which automatically change the program to be as parallelizable as possible BEFORE execution so that the whole chip can be used for just running things in parallel.

The comments on this slide keep me thinking about backwards compatibility of code. If you wrote software that used parallelism to 2x your speed and it continued to work on the latest hardware because said hardware was backwards compatible, then you'd always be twice as fast as the competition. But if because software isn't compatible your dev team is always catching up and using two year old hardware, then there's no benefit to parallelism instead of just upgrading to the latest hardware. I guess I don't have a great feel for this but my gut is telling me that sequential code is normally quite backwards compatible (you can upgrade to new hardware keeping roughly the same software). Can the same not be said of parallel code?

I think it depends what you mean by "parallel" code. If you mean ILPs then it's apparent that just after level 4 the return diminishes so there isn't really a point in increasingly parallelizing your code beyond that point without mentioning the fact that there's a limit to how "parallel" you can make your program. Some computations are inevitably non-parallel. Moreover, if you utilized SIMD to parallelize your code then I think we learned that your program won't work in previous CPUs that don't support SIMD.

@rthomp I think your feeling about backwards compatibility comes from the fact that sequential code is always able to be executed (every computer has at least one processor that has at least one fetch/decode, arithmetic logic, and execution unit), while for some levels of parallelism like SIMD, hardware modifications for multiple ALUs are required as @AnonyMouse mentioned. However, starting from the beginning of SIMD support, I believe that there is no reason why parallel code shouldn't be backwards compatible, since we've proven SIMD is effective and will continue using it.

why is parallel computing unnecessary when single core execution speed increases drastically? Shouldn't it make the program even faster? Or is there an assumption that change of hardware requires rewriting parallel computing code?
Please log in to leave a comment.
Is there a similar graph for the rate of performance increases on multi-threaded/multi-core CPU performance over time?