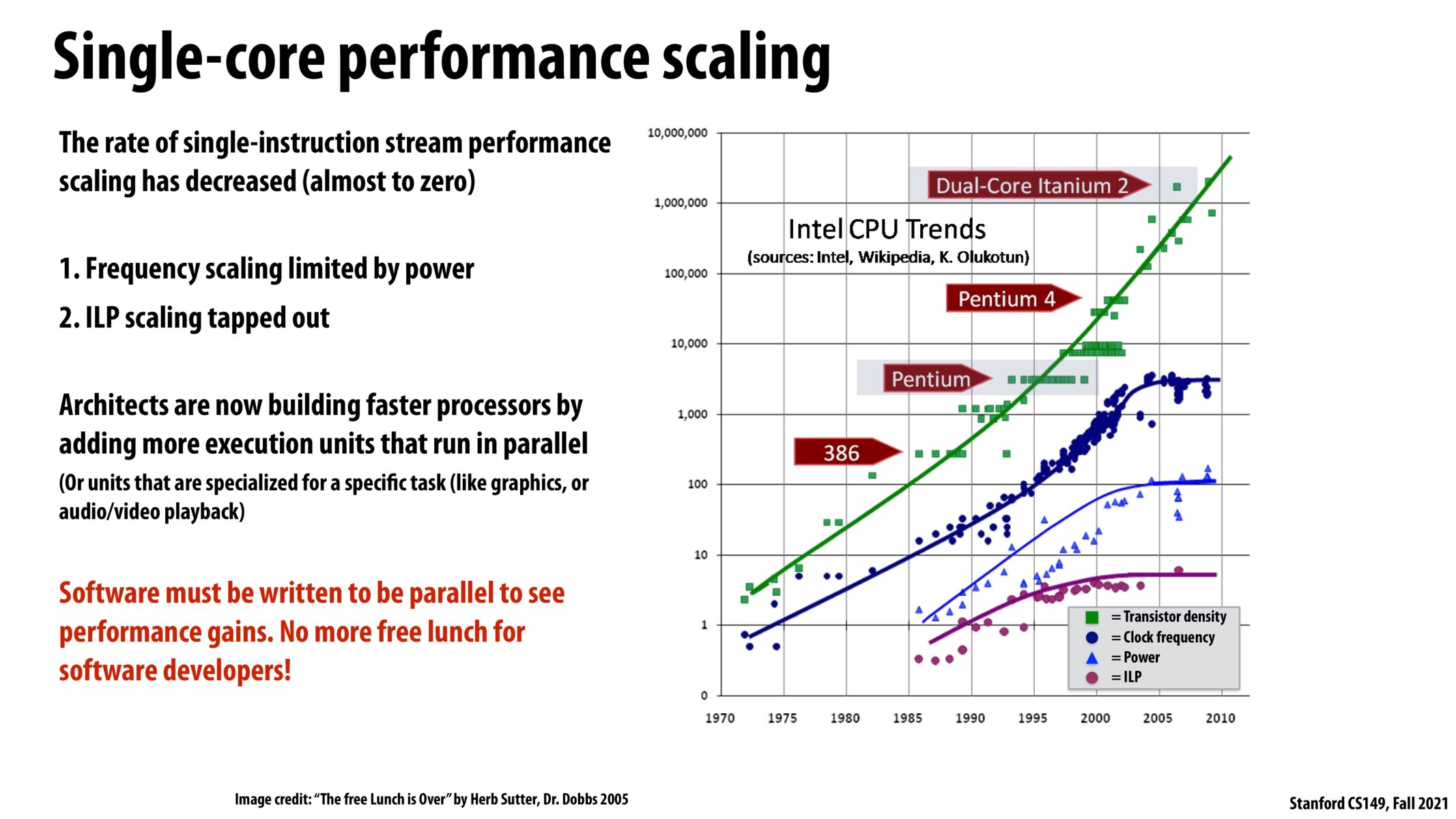


Although Morse's law is continuing, more attention needs to be paid to developing parallel algorithms and writing parallel codes as the ILP speedup gain plateaus. A great proportion of CPU time is spent running cedes that orchestrate the parallel tasks.

I was getting confused between concurrency and parallelism and found the analogies in this blog post to be helpful! https://medium.com/@itIsMadhavan/concurrency-vs-parallelism-a-brief-review-b337c8dac350

Well said by wkorbe. Just wanted to further emphasize the growing importance of developing specialized hardware to increase performance and efficiency for important workloads, as well as the need for new technologies which enable developers to more easily target heterogeneous hardware (wouldn't it be great if I could write one program that gets good performance on CPUs, GPUs, FPGAs, etc. ?).

One reason parallel programming has become increasingly important is that single-thread performance is seeing a power wall and has been struggling to increase. More update-to-date plots can be found: https://www.datacenterknowledge.com/supercomputers/after-moore-s-law-how-will-we-know-how-much-faster-computers-can-go Some interesting discussion on the trends: https://www.karlrupp.net/2018/02/42-years-of-microprocessor-trend-data/

Is there some kind of theoretical upper bound to the performance gain acquired by adding parallel execution units? Just as processor designers hit an ILP/power wall for single core, I would imagine there will come a point when even parallelism isn't powerful enough to keep up with society's speed/efficiency needs. I wonder what future paradigms will take its place.

I'm struggling to see the difference between "adding more execution units that run in parallel" versus the ILP constraints we saw before. The original method behind ILP was that a compiler would identify independent instructions that would be ran on different execution units - wouldn't adding more execution units suffer from the same problem of diminishing returns because there aren't enough independent instructions that can be executed in parallel in a given clock?

I wonder what gains can be made using application-specific hardware implementations like FPGAs. The execution units in a processor are very general-purpose, but with different clock speeds and different execution units for different specialized processes, there could be more speedups. Clearly, the investment into hardware implementation is prohibitively expensive.

^want to second lindenli's question. One possible reason I can think of is that adding more cores allows us to run more independent programs together, rather than parallelize a single program.

I'm wondering if the extra overhead from adding parallel execution units (as we saw in the demos) will also plateau machine performance. Regardless of balanced/unbalances workloads across the parallel execution units, they eventually have to communicate with one another which can also impact and potentially flatten performance gains, right?

How could computer programmers nowadays best write code so that their programs could be easily parallelized when new hardwares come out? What is the best way to parallelize the legacy code?
Please log in to leave a comment.
The free lunch was tasty, but there's something else to chew on now; it not only needs to be written to be parallel, but also might need to be written to execute across heterogeneous hardware, selecting the hardware the fits a task the best. The best could be achieving more efficiency/lower power consumption, and/or speed up versus using a general purpose cpu alone.