

@matteosantamaria you might be interested in taking a look at https://spark.apache.org/docs/latest/api/python/index.html. From my own (limited) experience using PySpark to process large datasets, the python interface for Spark seems pretty stable. I've also talked to a few people who have claimed to use PySpark + EMR (an AWS service for providing managed clusters running Spark and other tools for processing big data) in production. Take this all with a grain of salt though since it's all anecdotal evidence, but wanted to mention it in case you are interested in using PySpark in production environments.

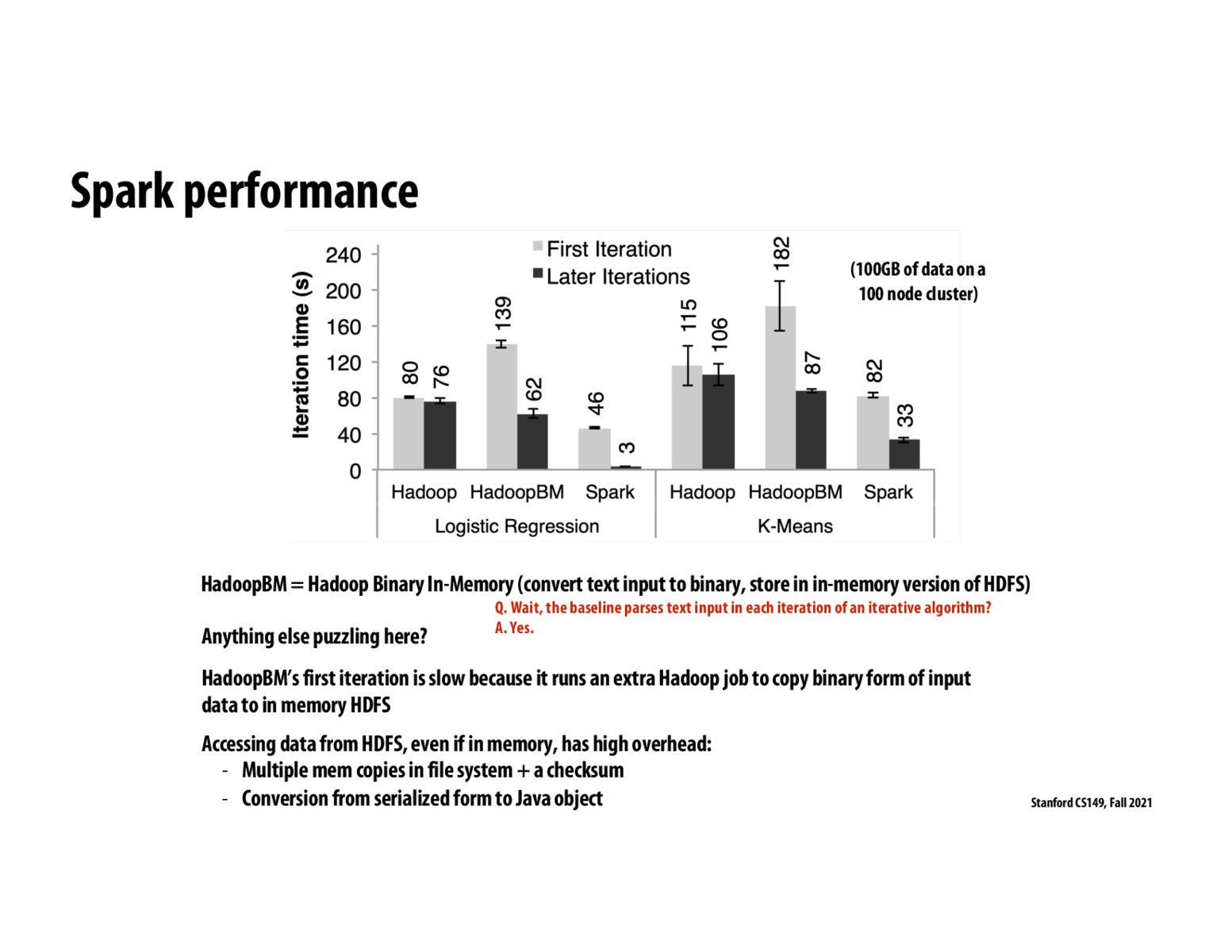
Key idea is that Spark's performance comes from in-memory representation of intermediate values compared to the slow disk reads for traditional map reduce or Hadoop jobs from HDFS. So, how does Spar's distributed memory system compare with Distributed Shared Memories such as Google's Percolator or RamCloud developed at Stanford or Piccolo etc. as seen in the bibliography of RDD paper by Matei Zaharia et al.

@matteosantamaria Your work should check out Databricks--it's the new version of Spark run by the original creators :)
Please log in to leave a comment.
These are really impressive statistics for Spark. At my work, we chose to use Dask over Spark though because Spark is written in Scala and can be difficult to use/debug if you're not familiar with the language. I believe Spark Python bindings are a work-in-progress, but I don't think its quite production ready yet.