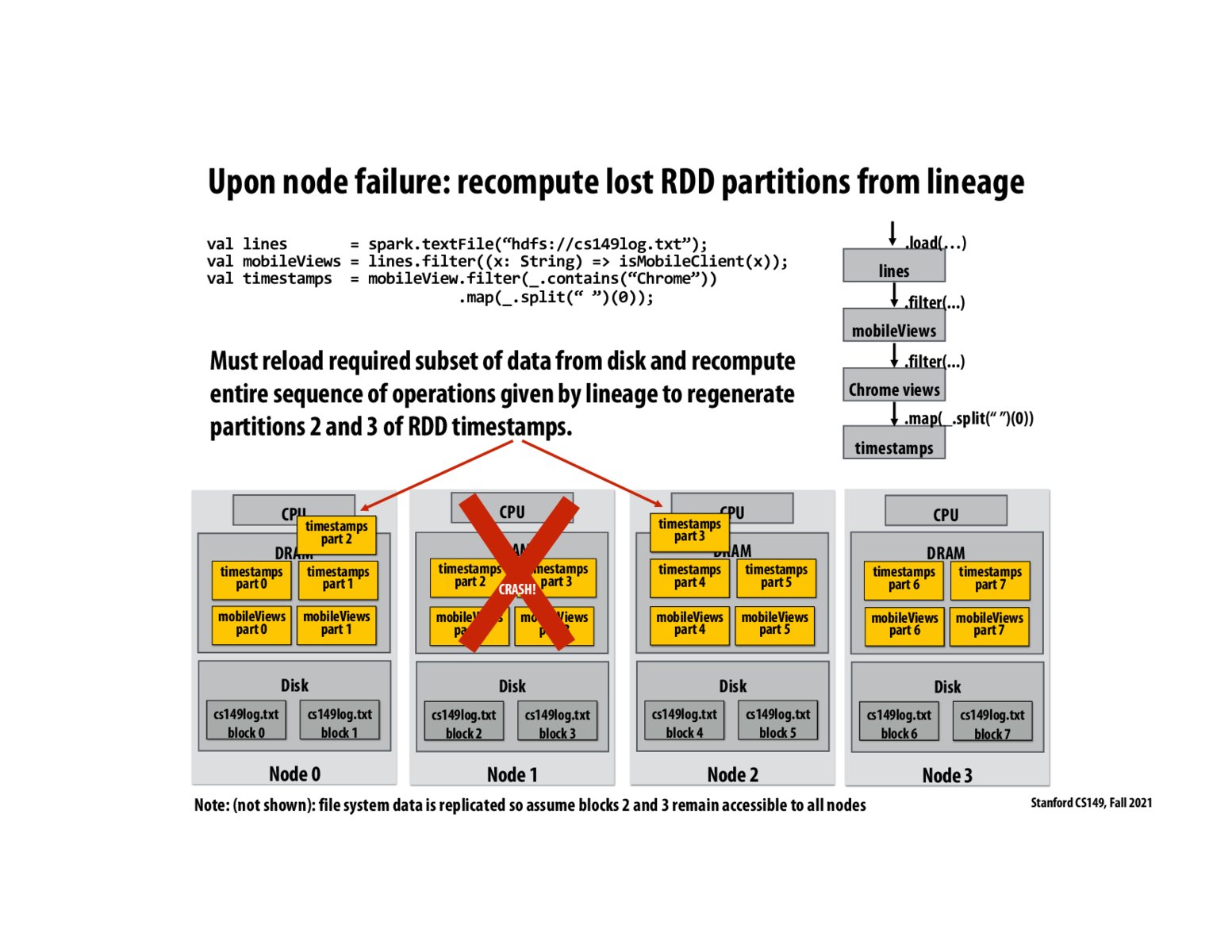

I totally agree with @cassiez and was wondering how exactly this system is fault-tolerant when even 1 node failing requires all partitions to be recomputed. It seems to me that most programs would have this kind of grouping or partitionBy() logic. I can understand how the re-computation of all partitions is necessary only if the fault occurs after the partitionBy() logic (because if the fault occurs before, you only have to recompute the partitions on the node that has faulted).

What if one node fails after a sort or group by but other nodes have intact RDDs for those steps? I guess there is no overlap in the data they would be processing later on so all the steps before sort / group_by would have to be redone? The other nodes would throw away the parts of the sort step they wouldn't then use later on?

Thank you cassiez for the explanation. So the recomputation of data across other nodes is based on the type of data/operation we are working with.
Please log in to leave a comment.
It looks like that when a node fails, if the RDD transformation lineage only contains operations such as map, filter... (can be carried out on data partition inside a single node), then only those partitions need to be recomputed. However, if lineage contains operations such as sort or groupBy that involves data across all partitions from all nodes, then even only 1 node failing requires data of all partitions to be recomputed (more expensive to recover from lost node).