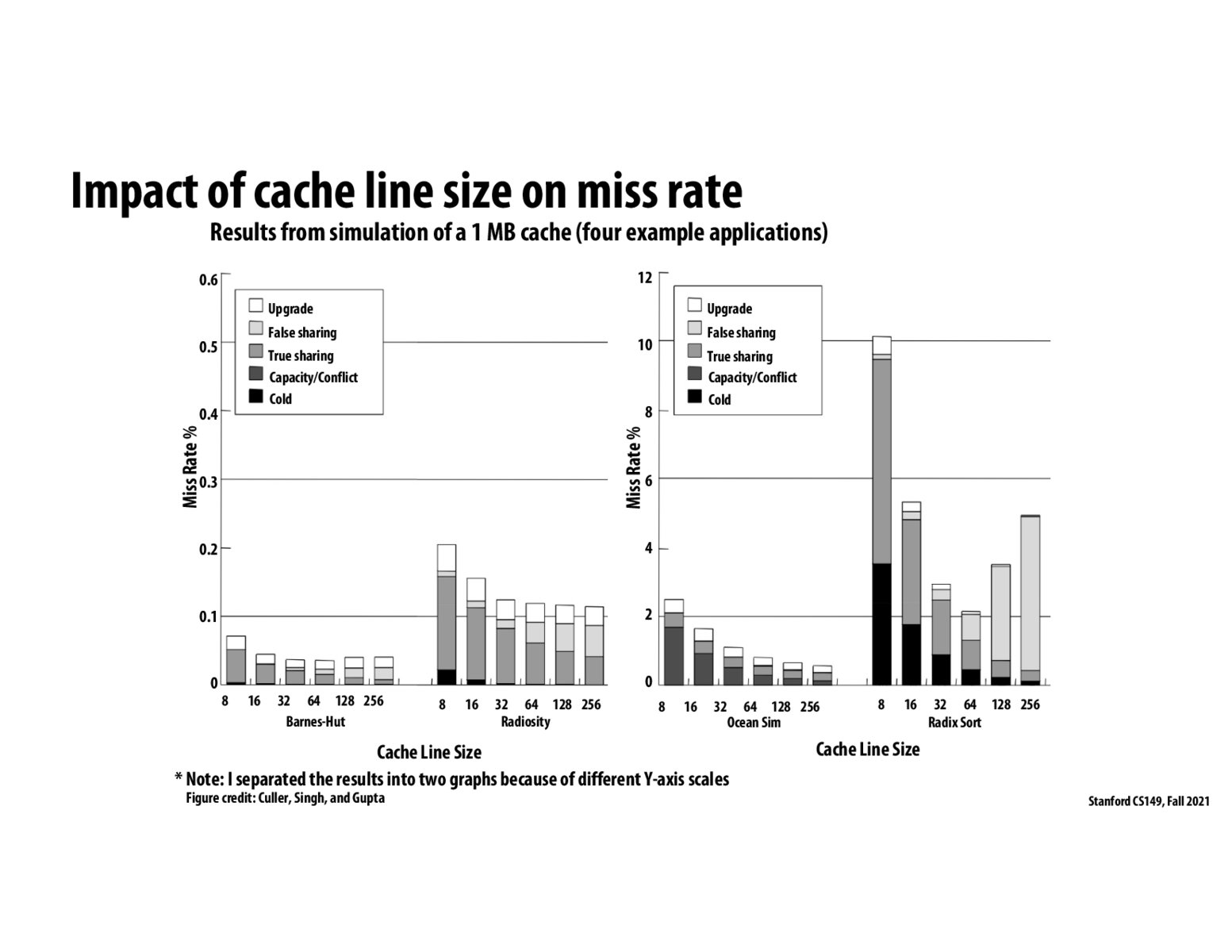


@ecb11 Here is a description of how normal Radix Sort is implemented. I am not quite sure how the parallel implementation would work, but I assume we would have to do iterations one at a time, meaning we would sort the whole array on the ones digit, then sort the whole array on the ten’s digit, etc. Depending on the sorting algorithm for a single digit, there could potentially be a lot of false sharing due to different processors wanting to write to nearby indices in the array. These elements might fall on the same cache line (especially with cache lines up to 256 bytes in size), so the processors would have to wrestle for control to have their cache line be in the M state.
My guess is that in the other applications, memory is split up more in chunks across different processors, so they don’t have to deal with false sharing as much. It’s also possible that the size of the problems has an impact on the amount of false sharing - if the input array for Radix Sort is a lot smaller, there will be more overlap across processors.
Please log in to leave a comment.
Curious about what sorts of algorithms (e.g. Radix Sort) might cause such dramatic increases in false sharing while maintaining high overall miss rates. The particular parabolic shape of the radix sort results are interesting for this reason (how there is a sweet spot with a cache line size of 64).