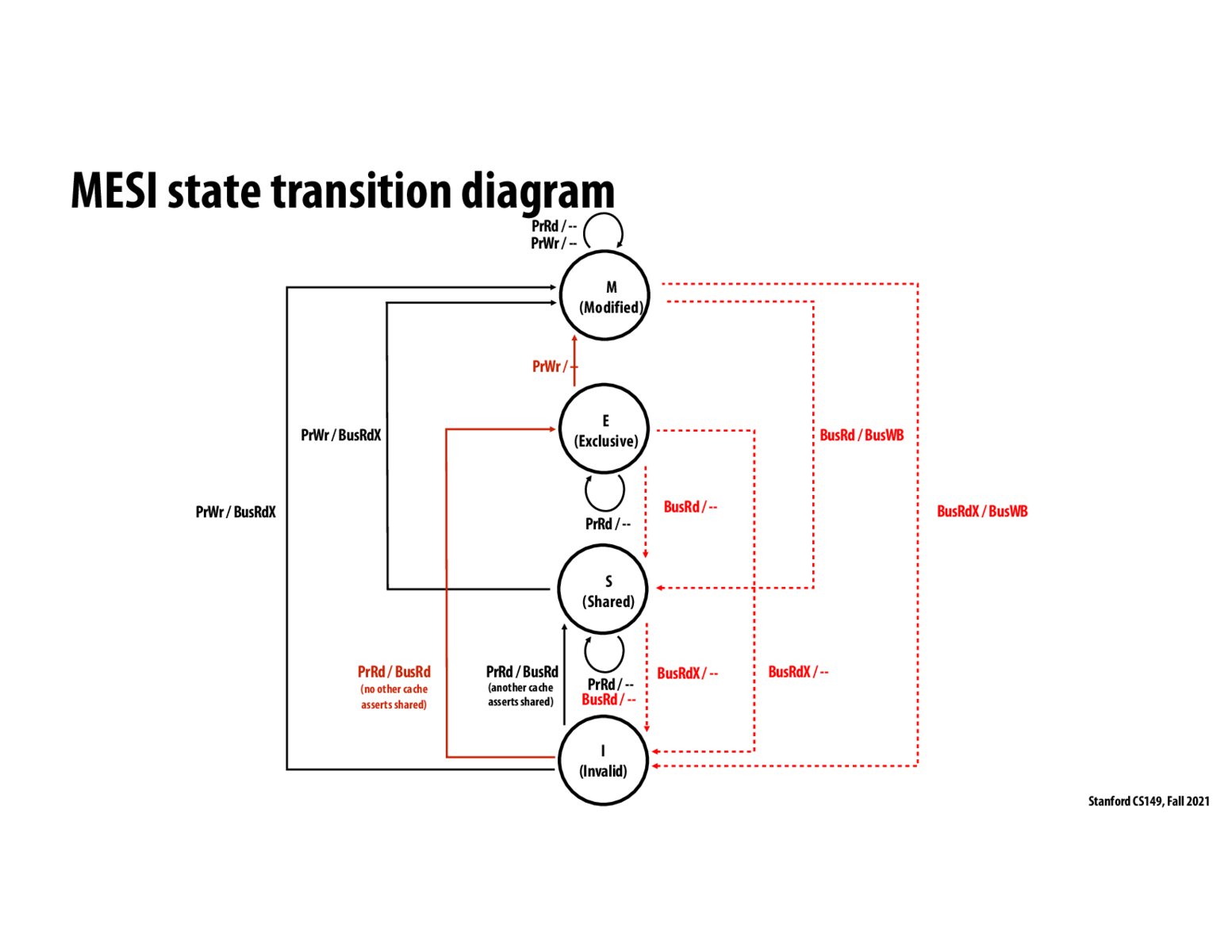


When a core is in the E state for a particular address, that means no other core/device cares about the value of that address (none are in the S state for the address). The core may go from E to M without telling any other core since they don't need to invalidate due to not caring about that address (not being in S). This reduces interconnect chatter.

Is it reasonable to say that a bus instruction is an instruction performed by another thread (for example, a WB instruction from another thread would make the cache line of the current thread from M to I)?

I'm still a bit confused about the scope of the MSI / MESI models. How is this logic implemented for every possible address?

Basically the sharing in MSI could be a false positive, as we have to go from I to S, even though no other processor caches have this cache line resident in them. With the addition of this 'E' stage, this situation is avoided and we can designate this false positive as a new state 'E'. This also means we save on messages, as in the E stet we know that no one else has the cache line and can move to M sate, let's say, without notifying other processors.

Addition of E state is mainly to reduce the number of bus transactions when a processor is reading and modifying a data which is not shared. Reading -> I to E which takes a bus transaction. Writing -> E to M does not require a bus transaction. It happens locally.
Please log in to leave a comment.
In practice, does adding the E state actually speed up processing times? It seems like quite a bit of added complexity at the hardware level.