

@jennaruzekowicz The encoding techniques similar to this one are widely used in serialization/deserialization format like Google Protobuf, Apache Avro to correctly encode the values while reducing the size of the serialized message. There's a whole page describing different ways Protobuf use to serialize the data in a very efficient format: https://developers.google.com/protocol-buffers/docs/encoding

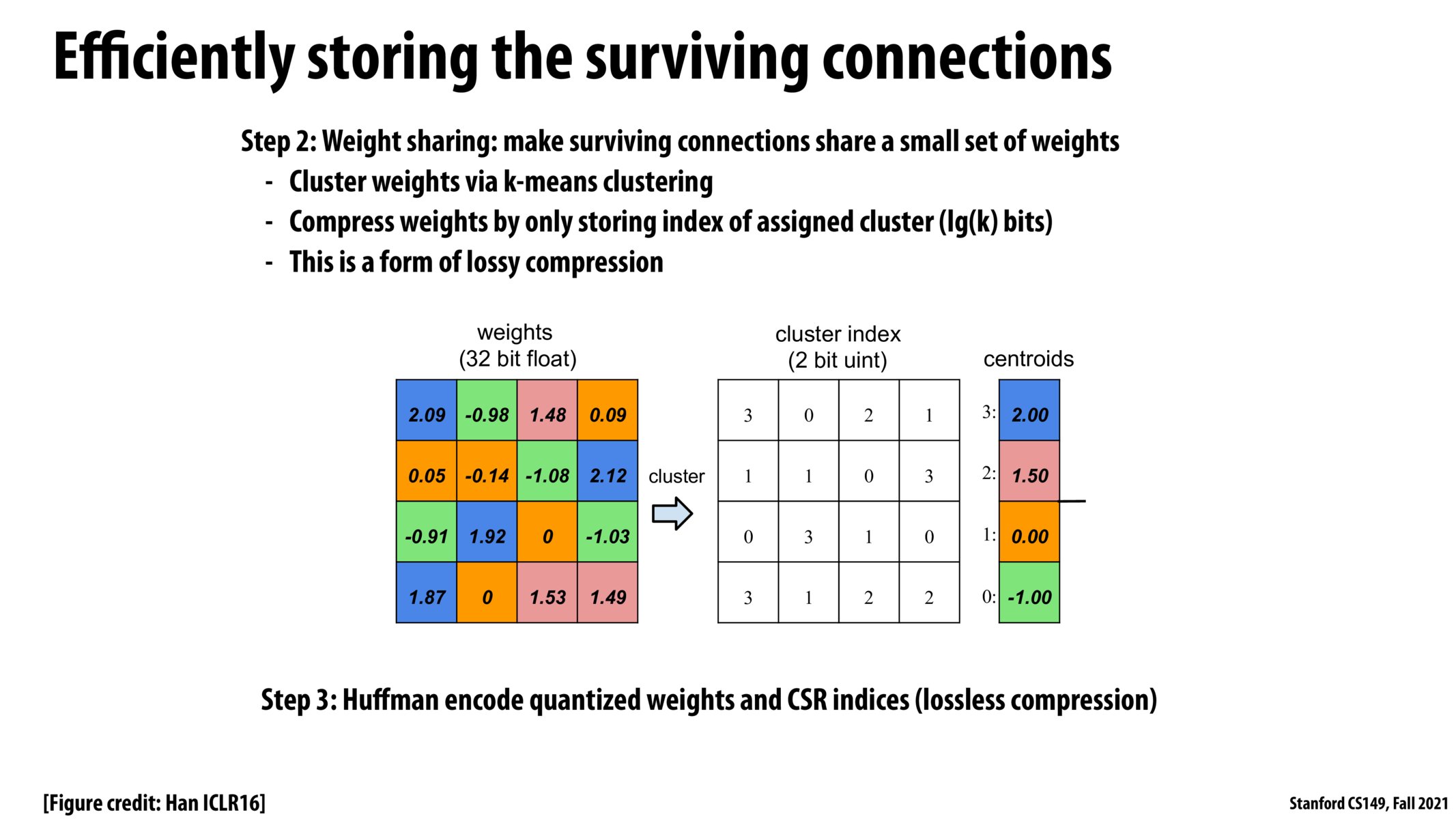
It seems like k means clustering is taken extra computation power. In addition, the preciseness of the data being stored is also compromised by the method of storing. Therefore, this method is an example of "doing more computations to save memory movements."

There are increasing tradeoffs between speed and accuracy here; however, a drop in accuracy may be like adding noise to the input and cause the final output to be more robust, so it may ultimately be better.
Please log in to leave a comment.
In what other applications do we store similar values like such? Is this common in machine learning to improve performance?