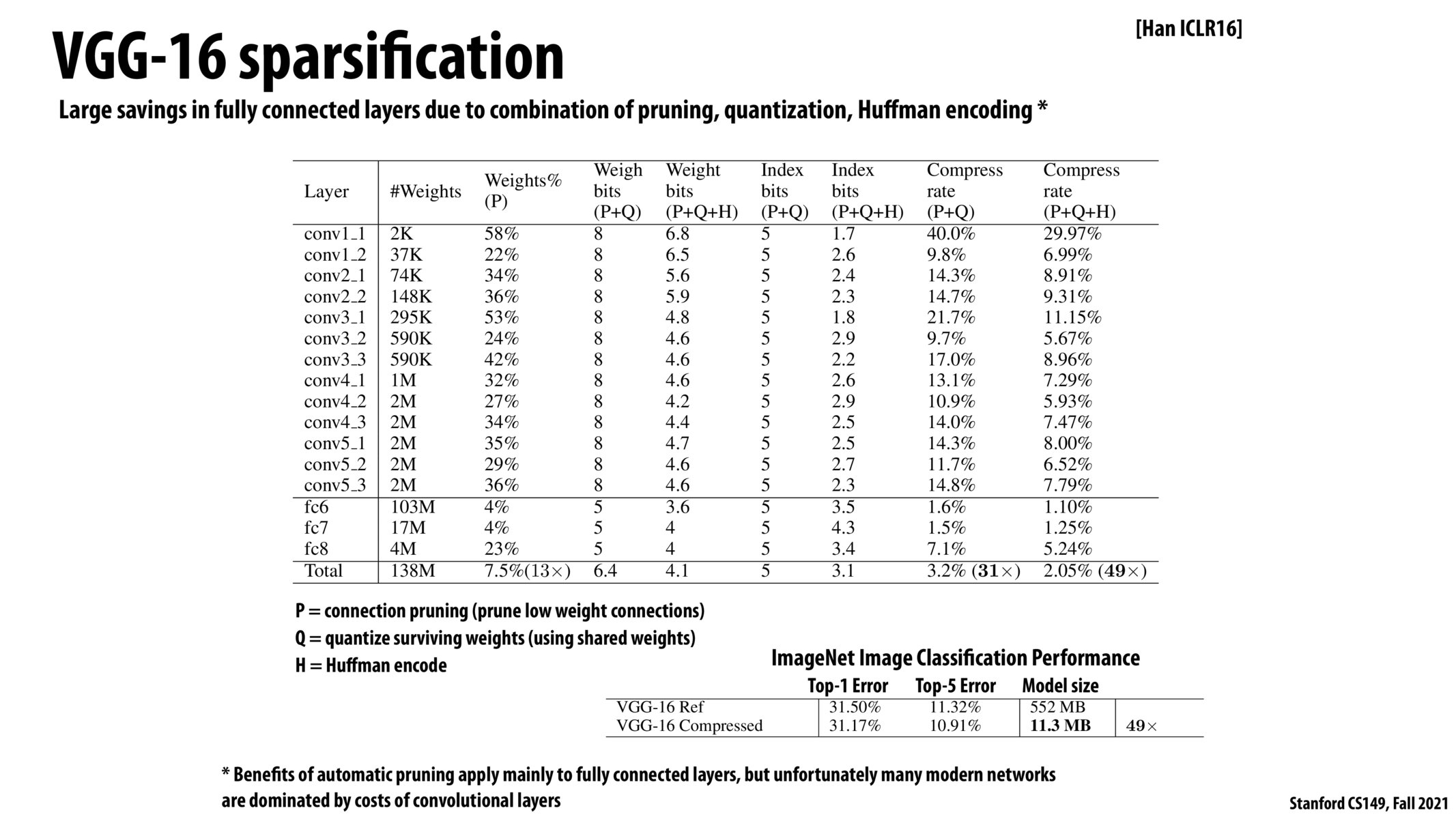


@gomi, wanted to pass along a paper exploring GPU usage in sparse matrix multiplication, where they achieved strong performance while keeping memory requirements low. You can check the paper out here: (An Efficient GPU General Sparse Matrix-Matrix Multiplication for Irregular Data){http://hiperfit.dk/pdf/SpGEMM_Liu_ipdps14.pdf}. I found it interesting that, above, we are employing the chosen compression techniques of P, Q, and H (shoutout to 106B!), but I'd imagine research and practice reflect a greater wealth of compression techniques beyond this. What are some of the strongest compression techniques for compute-bound programs, sparse-matrix-multiplication, or convolutional layer computations as we saw in lecture out there?

Might i be better to have different hw for different types of layers?
Please log in to leave a comment.
We saw earlier that dense matrix multiplications can be implemented extremely efficiently on GPUs since the data structure is regular and blocked. With sparse connections and sparse representation of data, I would expect that GPUs will struggle to provide good performance. How do we balance the sparsity (lower memory requirement) and training time? Or we are better off with specialized hardware?