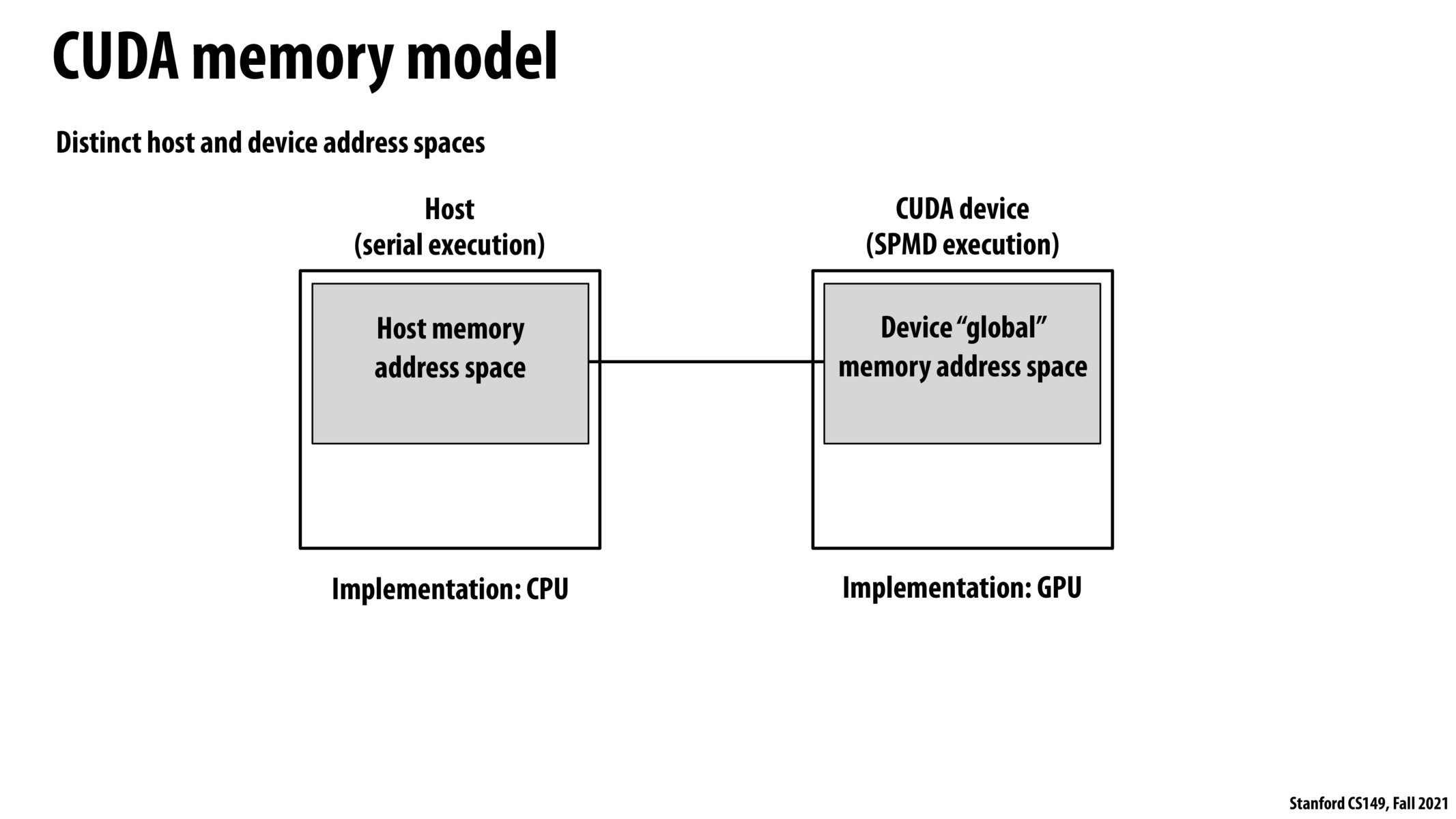

I believe the point of this diagram is to show that the address spaces referred to by the CPU and GPU are separate i.e. they both have distinct memory. Since a GPU has 'on-board' memory, it is possible to use solely the memory of a GPU for computation without needing to constantly refer back to memory from the host that the CPU needs to transfer. This is great, because memory bandwidth (transferring data from the host to the GPU) can be a bottleneck and will slow down computation, so having as much memory as is needed already on the GPU is vital. Running benchmarks can highlight how much of the time a GPU 'runs' is actually spent running and how much is spent transferring data or a model onto the GPU (it's a lot more of the latter for a smaller computation, so unless you are doing large enough computations to amortize the cost of transferring the model onto the GPU, it may not be worth it). Interestingly, Google's specialized chip for AI, a TPU, can be even slower when it comes to memory on load, but once the data is on the TPU, it will typically compute faster than a GPU.
Of course, there is a limit to how much memory can be transferred onto a GPU, which is one reason why when running ML models, we train in batches, and then clear the data from the GPU, as we may not be able to fit the entire dataset onto the GPU.

Can we think of GPU as a hardware accelerator designed for large independent parallel workload, while the CPU still acts as the 'brain' of the computer and offloads these work to the GPU (given that the program is designed to run on GPU)

I can imagine the CPU-GPU communication time might be a significant issue if we constantly have to communicate information from the "driver" (CPU) to the GPU that is capable of servicing these requests. Does limited bandwidth prove to be an even bigger in this situation here? Or do we generally want CUDA programming to have really large arithmetic intensity?

This paper here: https://crd.lbl.gov/assets/Uploads/PMBS20-NVSHMEM-final.pdf seems to indicate that CPU-GPU communication can be a bottleneck in very high performance machines, but there are some alternatives, such as direct-GPU communication, which can be helpful in nodes with many GPUs.

Although this diagram shows the CPU using serial execution, I assume it would be possible to implement some kind of parallelism on the host CPU and also on the CUDA device? Since everyone has mentioned this bottleneck of CPU-GPU communication time, could it be the case that for some kinds of problems, it makes sense to do some of the work in parallel on the CPU and only send out the arithmetic intensive computations out to the GPU? Or would programmers not even bother using the CPU at this point if they have the power of the GPU available to them?

With the new generation M chips from apple, I have heard about "unified memory" meaning that we don't need to copy memory from GPU and CPU. Are there any advantages to this system over having unified memory?

When we want to parallelize our work onto multiple GPUs (i.e. distributed training for ML models). How do we transfer data onto multiple GPUs?

This blog gives some basic suggestions on how to optimize data transfer between CPU and GPU: https://developer.nvidia.com/blog/how-optimize-data-transfers-cuda-cc/. While this makes a lot of sense, I have the same question as @jtguibas on the advantages of this separate CPU-GPU memory model over them sharing the same address space.

While its not as much an 'advantage' as a tradeoff, having separate physical memories for GPU and CPU means that GPU and CPU don't compete for memory bandwidth. The 'unified memory' model forces the GPU and CPU to share memory bandwidth.

I also have seen that Apple is really bragging about the unified memory, and that also their memory is something like 10GB, whereas I'm used to seeing memory be some power of 2. Is this purely for saving space? Does it provide any actual performance benefit over having separate address spaces?
And, why is it not some clean number, like 16gb?

@huangda +1 good question - would want to know more
Please log in to leave a comment.
I didn't quite understand what this distinction is between host and CUDA device? Is this explaining what the difference is between the same code running on a CPU vs a GPU (CUDA device)? What is the host? Why is the inherently serial when we've seen many CPUs that allow for SPMD execution?