

@shivalgo yup, and you can also copy between devices with cudaMemcpyDeviceToDevice if you have a multi-gpu setup: https://docs.nvidia.com/cuda/cuda-runtime-api/group__CUDART__MEMORY.html#group__CUDART__MEMORY_1gc263dbe6574220cc776b45438fc351e8

since m1 processors don't have this memory separation, would you need to write different openCL code for them that doesn't use memcpy (or openCL's version of memcpy)?

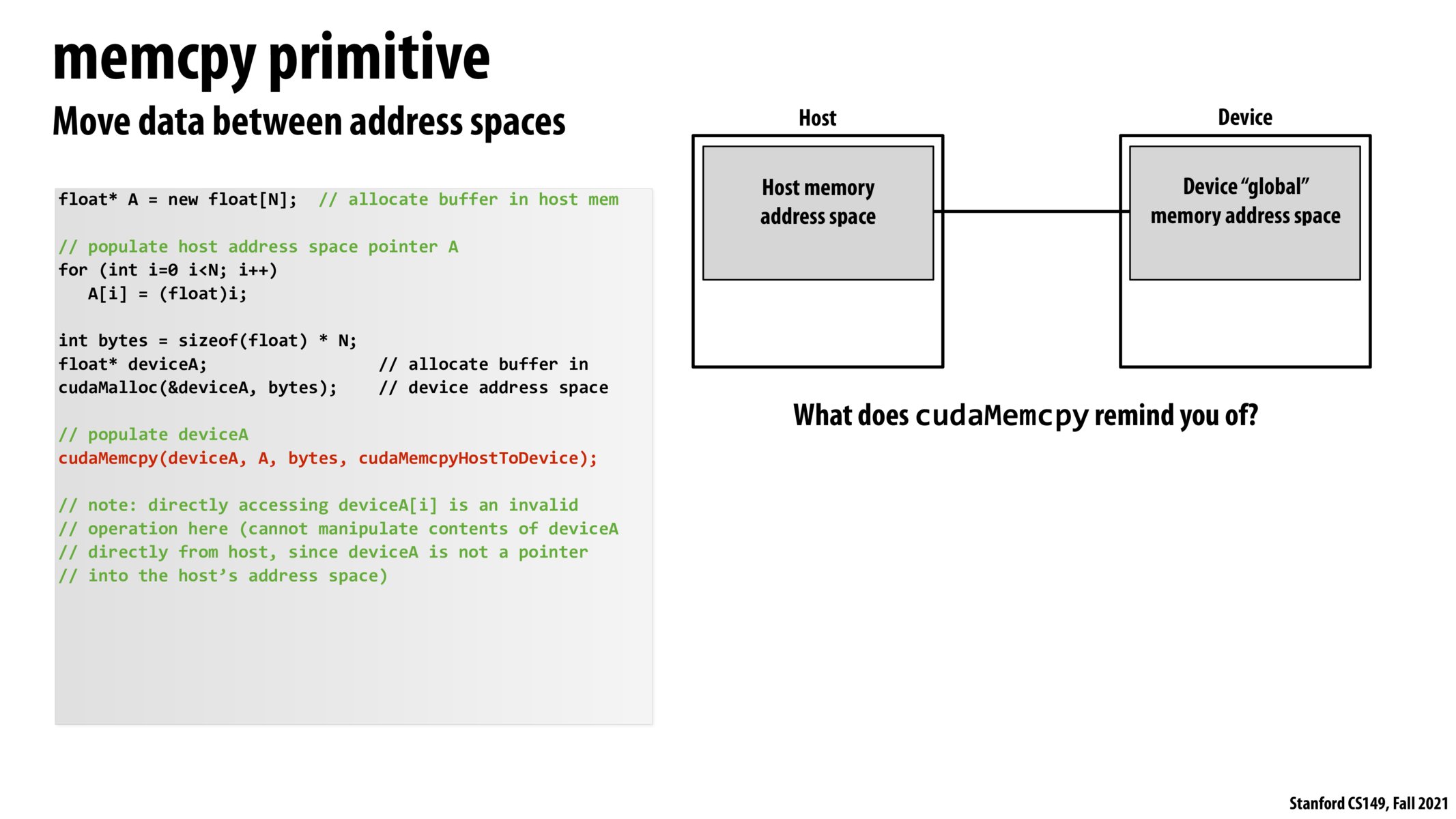
Is the cudaMemcpy(), the underlying function that the PyTorch runtime calls when you want to send a tensor object to the GPU. (e.g)
device = torch.device("cuda:0") arr = torch.tensor([1,2,3]) arr.to(device)
Does arr.to(device) just call cudaMemcpy()?

cudaMemcpy reminds me of a message call in the messaging model due to the fact that it is used to share data across separate memory spaces.

Are there alternative models to this kind of memory/comms scheme?

@ardenma I don't think that's used for copying between devices in a multi-GPU setup, it's more for copying data from a location in device memory to another location in device memory on the same device. For multi-GPU setups, what you're looking for is probably cudaMemcpyPeer/cudaMemcpyPeerAsync where you could pass in the source and destination device IDs as in the IDs corresponding to two GPUs in the same system. This essentially performs a copy between two devices. You can find more about this in this link https://www.nvidia.com/docs/IO/116711/sc11-multi-gpu.pdf slides 19-20
@rubensl oops yes you're totally right, I just looked at the naming and assumed it was for multi-gpu transfers. Kind of a weird way to name things...
Please log in to leave a comment.
So, looks like cudaMemcpy could be used bidirectionally by specifying either the cudaMemcpyHostToDevice or (I am guessing) the reverse of it - cudaMemcpyDeviceToHost - flag?