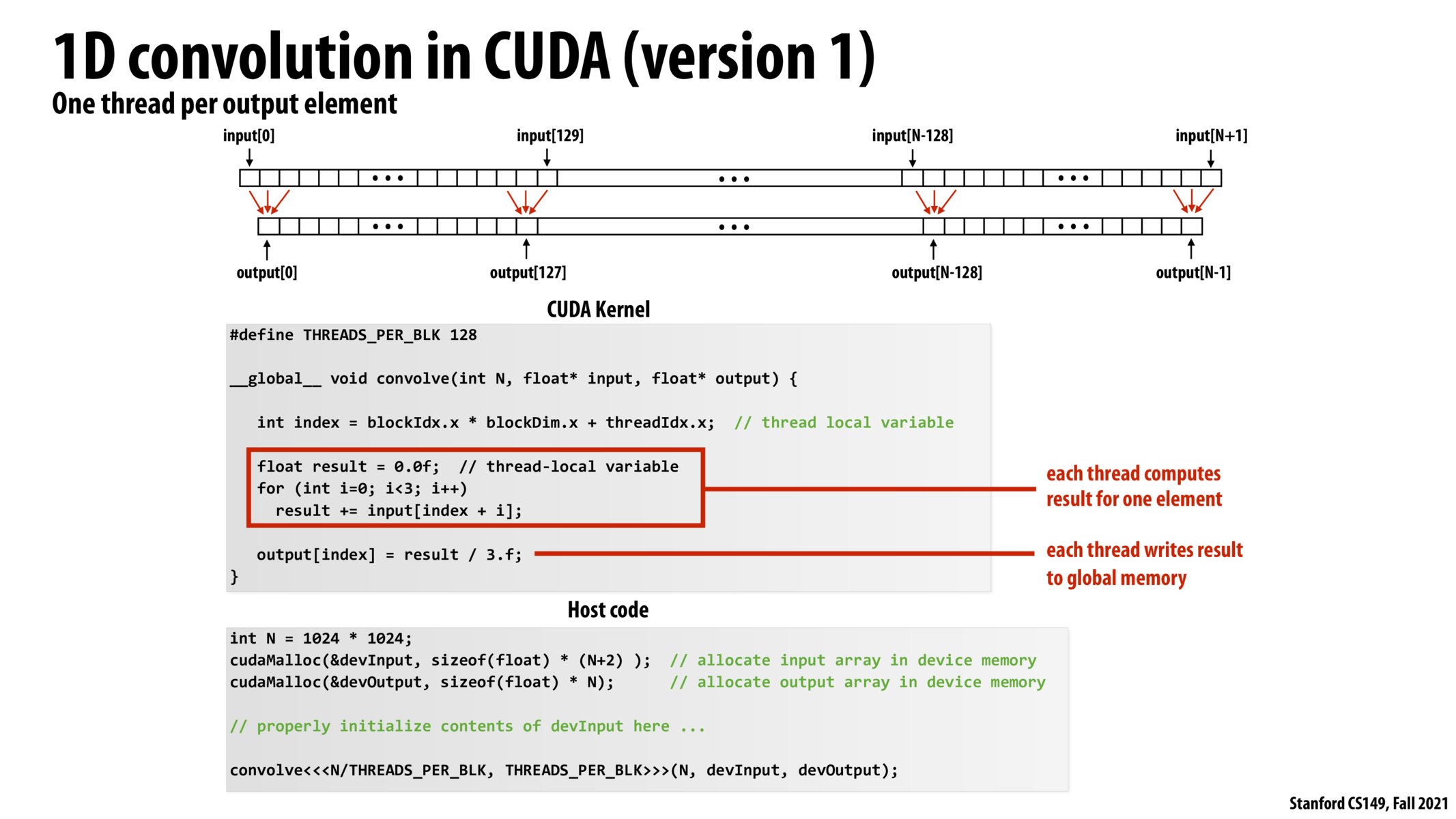

Here, for computing the output, each thread in the block loads 3 input[] elements from the global device memory. So every block loads 3*128 times from the global device memory. As this incurs a huge amount of latency, there is shared 'per block' memory available, which is discussed in the next slide.

I don't quite understand what you mean by utilizing the 1-D aspects of the thread grid size/thread index....would love some clarification!

The difference between a device and host function was confusing for me at first, but made a lot more sense after starting A3 - a host function is like the "main" code that executes on the calling thread, and a device function is a per-thread function (similar to a child thread that spawns). It's actually a much clearer way of understanding what each of the threads do!

Something that was confusing to me in lecture was the use of N/THREADS_PER_BLK and THREADS_PER_BLK here, when we had previously used dim3 parameters. To clarify,
dim3 is an integer vector type based on uint3 that is used to specify dimensions. When defining a variable of type dim3, any component left unspecified is initialized to 1.
So, we're only working with a 1-D version of the CUDA grid. @ccheng18, this might apply to your question as well.
See more at http://docs.nvidia.com/cuda/cuda-c-programming-guide/#dim3.
Please log in to leave a comment.
The two parameters in convolve <<>> are not passed to the function, but are used to provide the built-in variable blockDim.