Back to Lecture Thumbnails

jaez

abraoliv
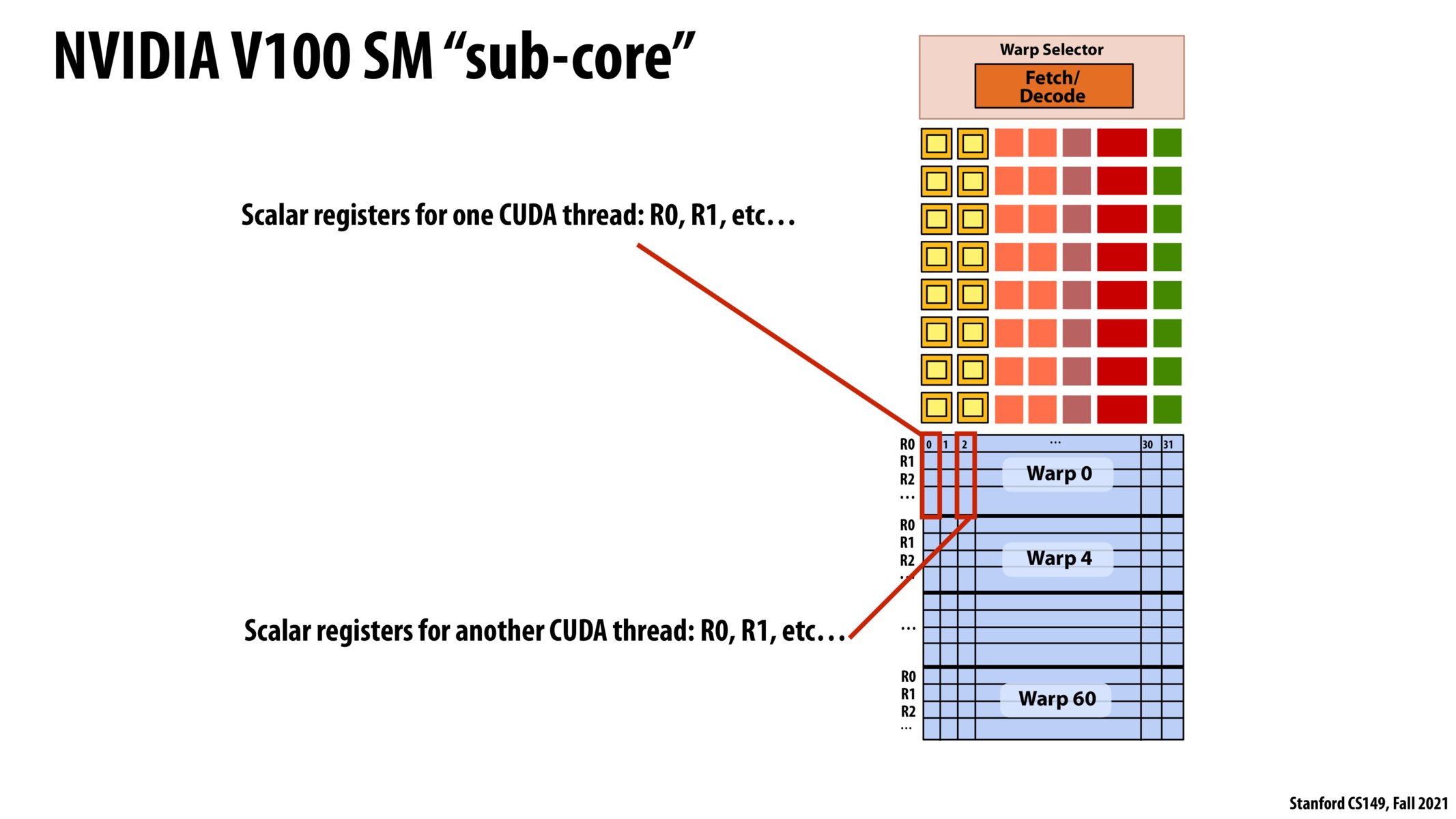
@jaez If I understand correctly, the SIMD occurs across all the threads in the warp, not within any individual thread. Said differently, each thread operates on a scalar but if the same operations is being done across the threads in a warp, their scalars combine to make the vector for SIMD processing.

ghostcow
Right, this is my understanding as well. SIMD is executed across all threads in a given warp (similar to a "window size" in ILP); when n of these threads are running the same operation, that operation is executed using vector registers in one of the yellow execution units.
Please log in to leave a comment.
It is mentioned here that the registers are scalar registers. Why are vector registers not used, given that the instructions are executed in a SIMD fashion?