
My mistake. The ALUs are SIMD f32 functional units.

So let me try and summarize the difference between CPU SIMD / ISPC and cuda warp / thread:
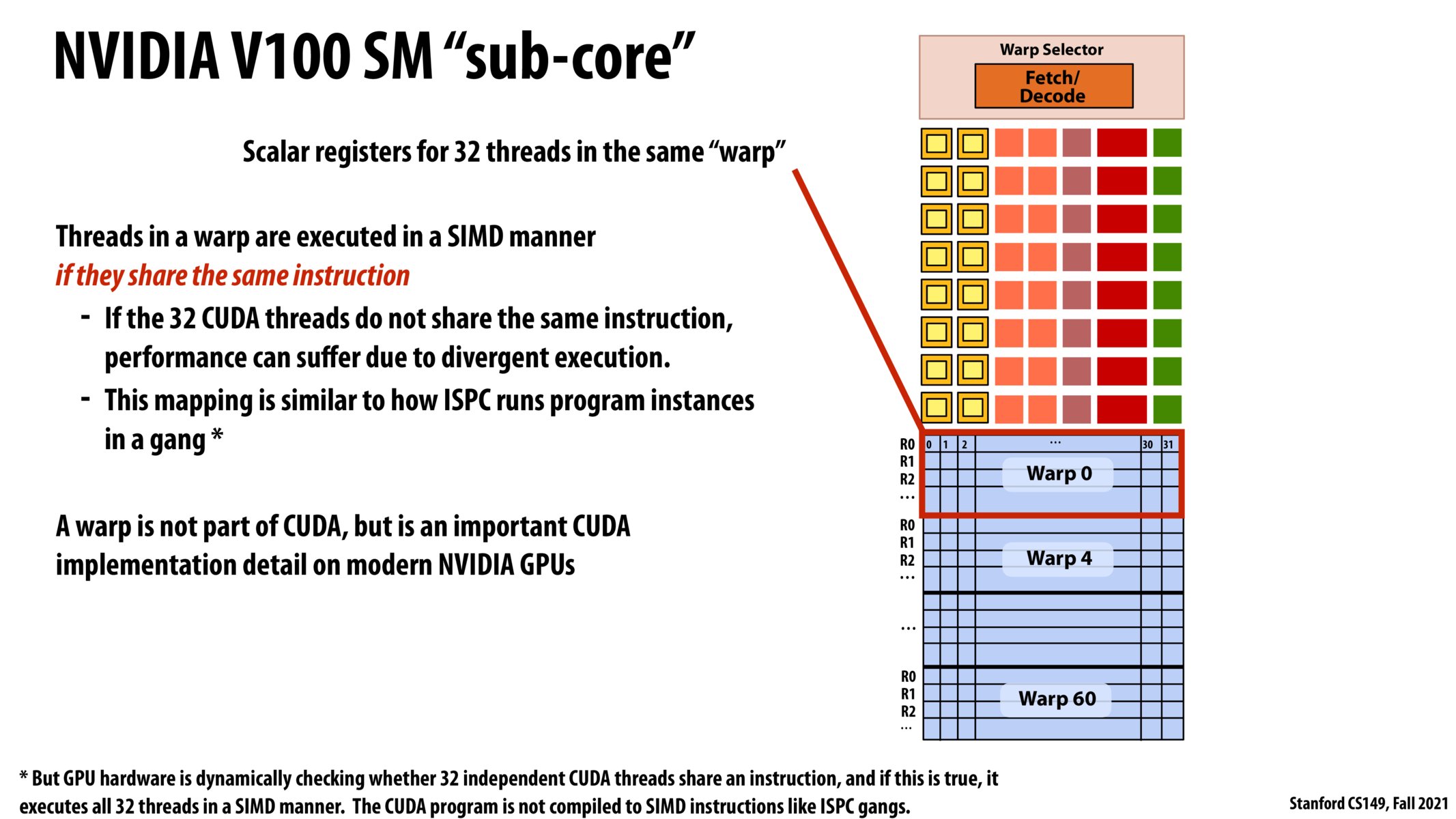
CPU SIMD / ISPC: - 1 core has a vector ALU (can have more ALUs, but keep things simple) - Vector instructions can operate across all lanes (ISPC instances) WITHIN 1 execution context (or do we call this 8 execution contexts for 8-wide SIMD?). So this is SIMD within 1 thread.
CUDA: - 1 core has many scalar ALUs (need vector ALUs?) - if all execution instructions the same, 1 CUDA thread = 1 SIMD lane - 1 GPU can have up to NUM_WARPS * 32 execution contexts. - Vector instructions can operate across all lanes / threads in a WARP. In fact, this is the way it is run. SIMD is the only way a warp executes instructions, so there is necessarily SIMD divergence the 32 instructions are not the same.
???
Ah I tried to do bullet points by using dashes. Didn't work; please treat the dashes as new lines!
Please log in to leave a comment.
Do CUDA threads instructions run on SIMD vector ALU or parallel scalar ALU units then?