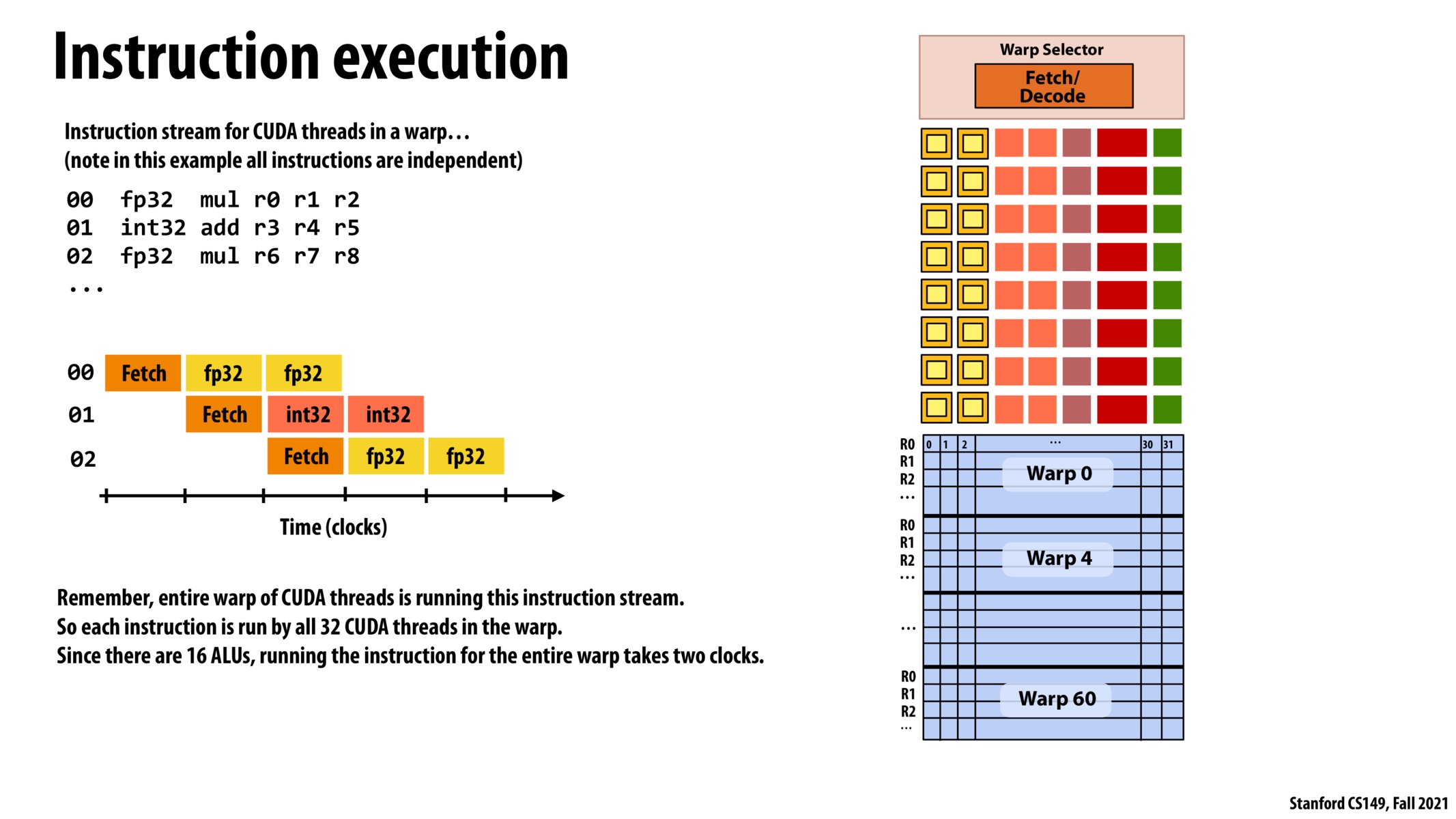


Is there a way to change the number of CUDA threads in each warp? Or is that fixed by hardware? If so, why don't we design the device to have 32 ALUs?

@student1 and @stao18, I think the benefit is this: By having 16 ALUs, 32 size warp and one fetch/decode unit - we are spreading each 32 bit wide instruction's execution to 2 cycles. Yet, the steady state throughput will be 1 instruction per cycle. We can achieve the same steady state throughput with 32ALUs, 32 size warp, one fetch/decode unit and by executing each instruction in 1 cycle. But the utilization of hardware is double in the first case. So when we can achieve the same throughput with half amount of hardware, why not do that?

In this case, ALU's are fully utilized, but if there are two consecutive fp32 executions, then the execution flow has to stall for one cylce.

Can you think of one warp as the threaded execution context on one CPU, and the collection of ALUs as the processor on a CPU? I feel as if that is how we've been treating the written assignments.
Please log in to leave a comment.
Is there a reason why the wrap is selected to contain 32 context switch with 16 SIMD? This seems to lead to the situation that one fetch instruction can allow the GPU to perform two floating point computation. Is there a particular reason for this?