The idea here is that a large inefficiency we have not addressed in the class till now lies in the overhead of using these parallel computations. E.g. even in SIMD, we only use like 5-10% of the computation. Ideally, we can directly hardcode out operations on the hardware, and skip a ton of this overhead work.
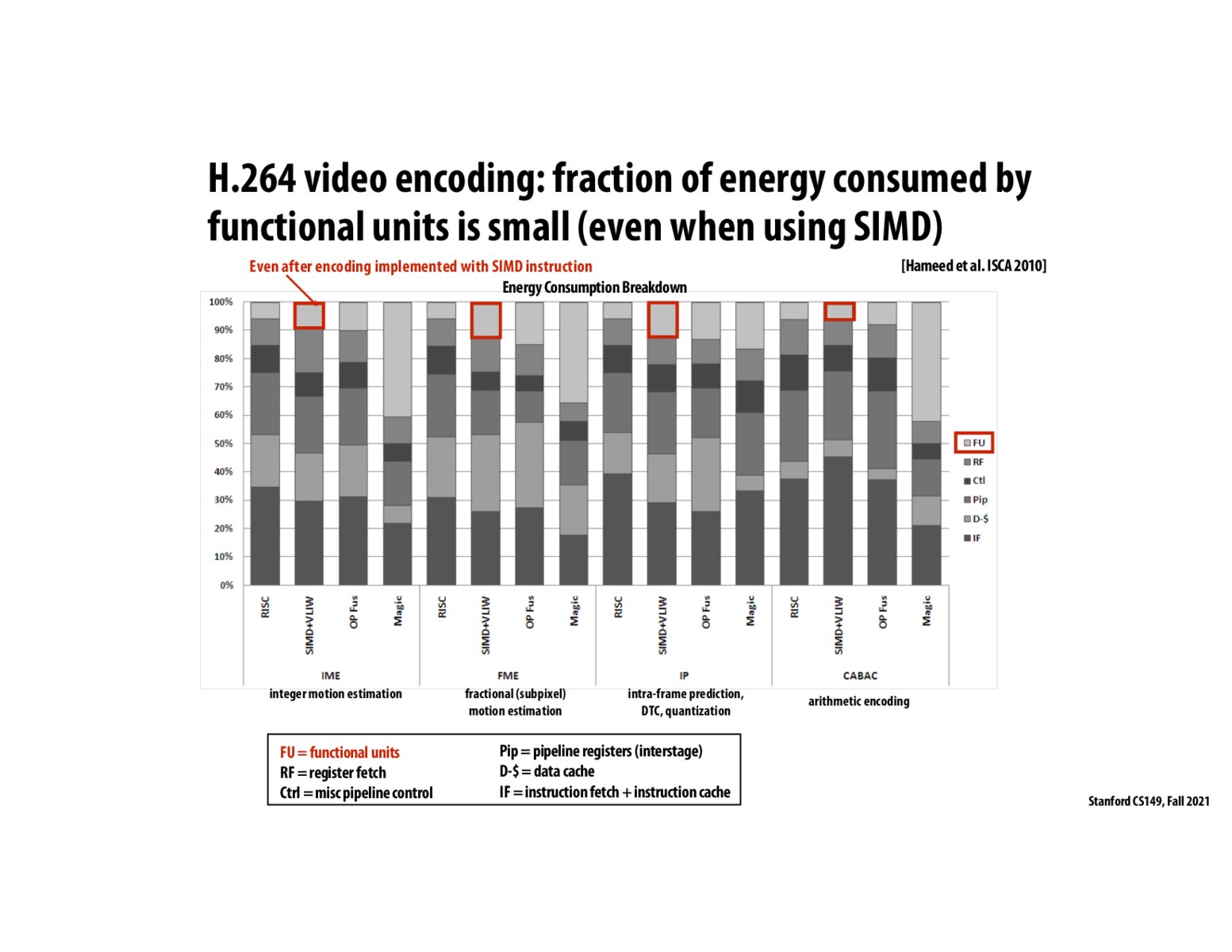

The idea here is that a large inefficiency we have not addressed in the class till now lies in the overhead of using these parallel computations. E.g. even in SIMD, we only use like 5-10% of the computation. Ideally, we can directly hardcode out operations on the hardware, and skip a ton of this overhead work.