
Instead of slower hardware, think about chips of the past having less hardware (fewer transistors) to implement complex out-of-order scheduling algorithms. Both twenty years ago, and today, processors were required to make instruction scheduling decisions every clock.
That makes sense and is a much better description at what i was wanted to get at! I should have said "much less" hardware!

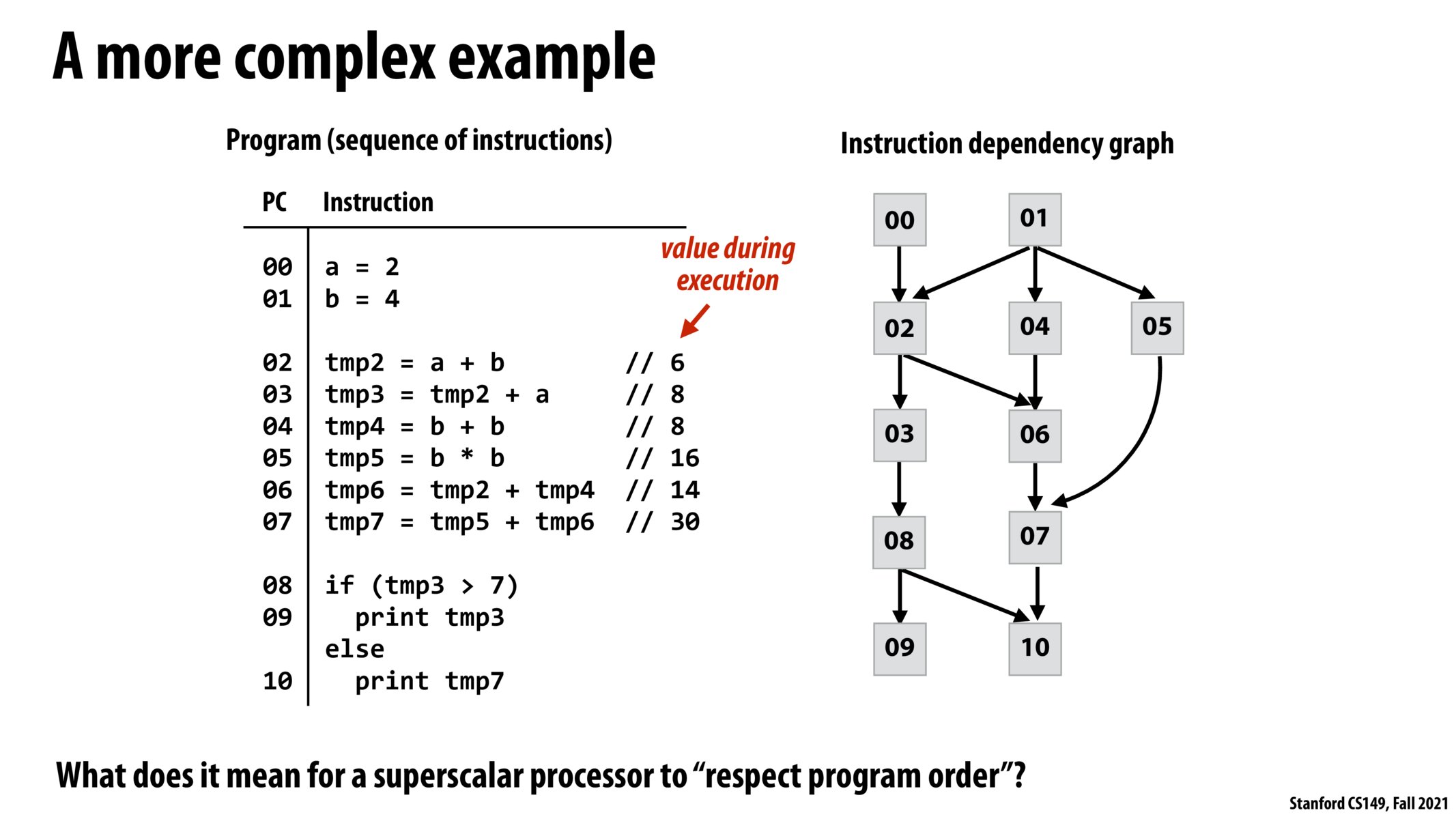
Does the superscalar processor determine the instruction dependency graph from the whole program? If it breaks it down into smaller chunks how does it determine how to break down the program? If it doesn't, how does it get access to the entire instruction set at once?

@ckk I'm curious about your last question too ("how does it get access to the instructions?"), but for the other things I think in lecture it was said that there is a reading window that the superscalar processor restricts itself to when determining how to break down the program and find anything that can be parallelized
@ckk, lordpancake -- A processor will attempt to find independent instructions within a limited "window" of instructions. (we're talking tens of instructions, no where close to a an "entire" program). Think about it like this... the processor is able to look ahead to fetch the next 10's of instructions in the instruction stream and analyze which of those are independent and how they depend on currently executing instructions. This is a sliding window... when any instruction completes then the processor fetches the next instruction in the stream and adds that to the analysis.
For example, this documentation suggests that the modern Intel processors are attempting to schedule about 100 operations across their two hardware threads.
https://en.wikichip.org/wiki/intel/microarchitectures/skylake_(client)
Please log in to leave a comment.
Kayvon mentioned how computing/figuring out the dependency graph for the instruction stream can become expensive, which is interesting to think about considering how long people have been researching this. They were probably figuring this stuff out on much, much slower hardware so for them to be able to find ways to outweigh this cost even back then is quite impressive.