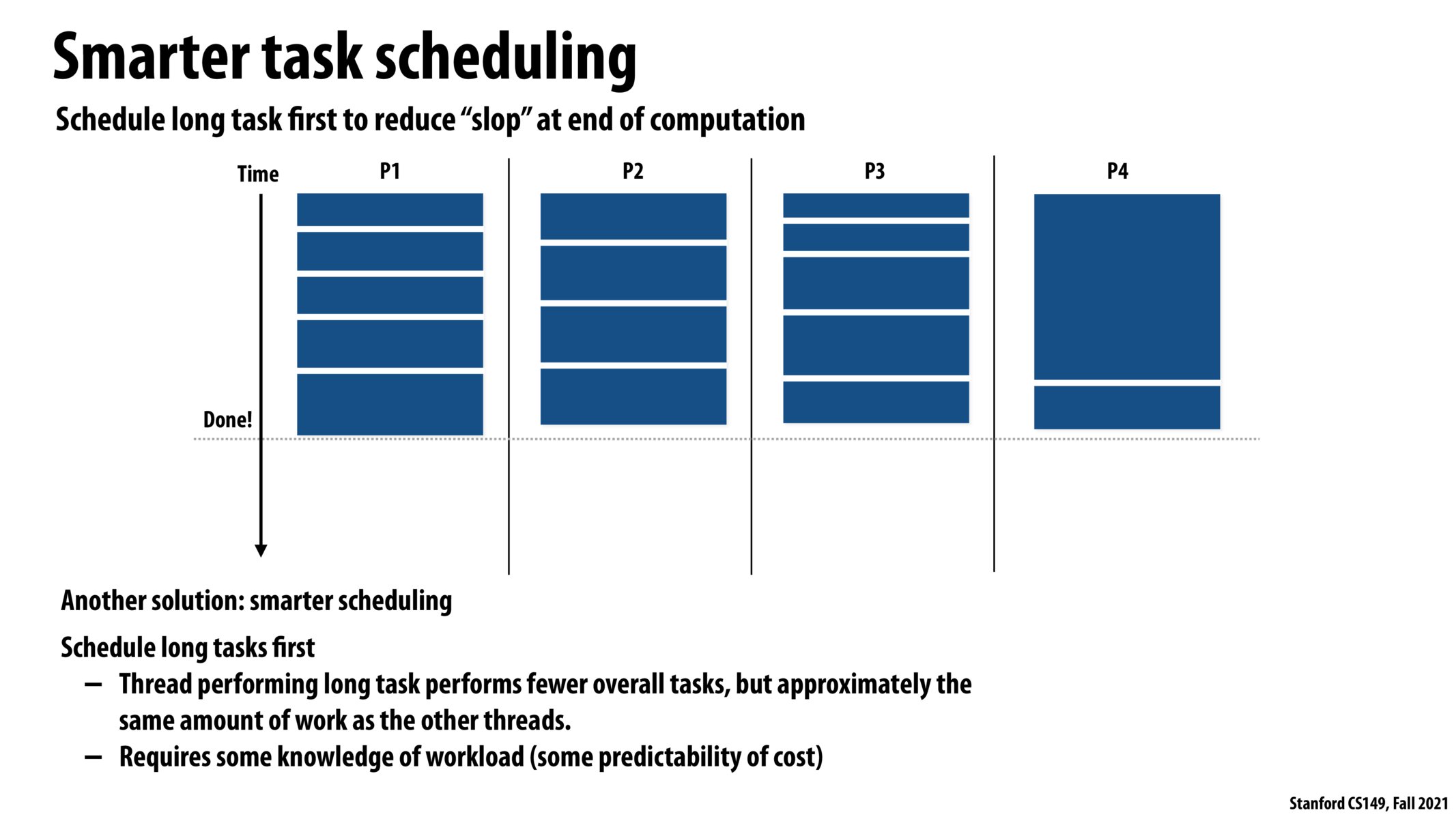


It makes perfect sense that we would want to schedule the larger tasks first, however, how does the scheduler/compiler know what tasks are larger? How do we determine the relative size?

Additionally, is there a way for the programmer to inject this info s.t. the OS is aware of the cost of each task that is spawned (for example with ISPC)? I can imagine manually setting a cost of every task I create with ISPC and have the OS schedule the tasks via a priority queue of sorts.

It seems like there is some harder combinatorics problem that we could solve here for the truly most efficient scheduling. I guess scheduling long tasks first is a good heuristic here.

For tasks where sizes are determined at runtime (e.g. size depends on input) it is impossible for the compiler to know which tasks are longer. In such cases I think the scheduler should be dynamically assigning tasks to threads, but I would also imagine that the scheduler would not want to spend too much time on planning because that eats up some of the runtime

Is this an example of static scheduling since we are supposed to know the workload (and the total numbers of tasks) before assigning tasks to the threads?

@kristinayige, yes, I believe it is an example of semi-static scheduling (see slide 9). The cost must be somewhat predictable to schedule long tasks first, whereas in dynamic assignment (slide 10), the cost is unpredictable.

I'm guessing in this case that the overhead of sorting the tasks by length is easily offset by the performance boost associated with a balanced workload?

If the programmer knows about the work each thread is going to do, is there a way to communicate this to the OS (maybe thread priority?)
Please log in to leave a comment.
If we know the workload of tasks beforehand, is their some heuristic we can use to determine if the overhead of organizing tasks to assign larger workloads first is worth work execution speedup.