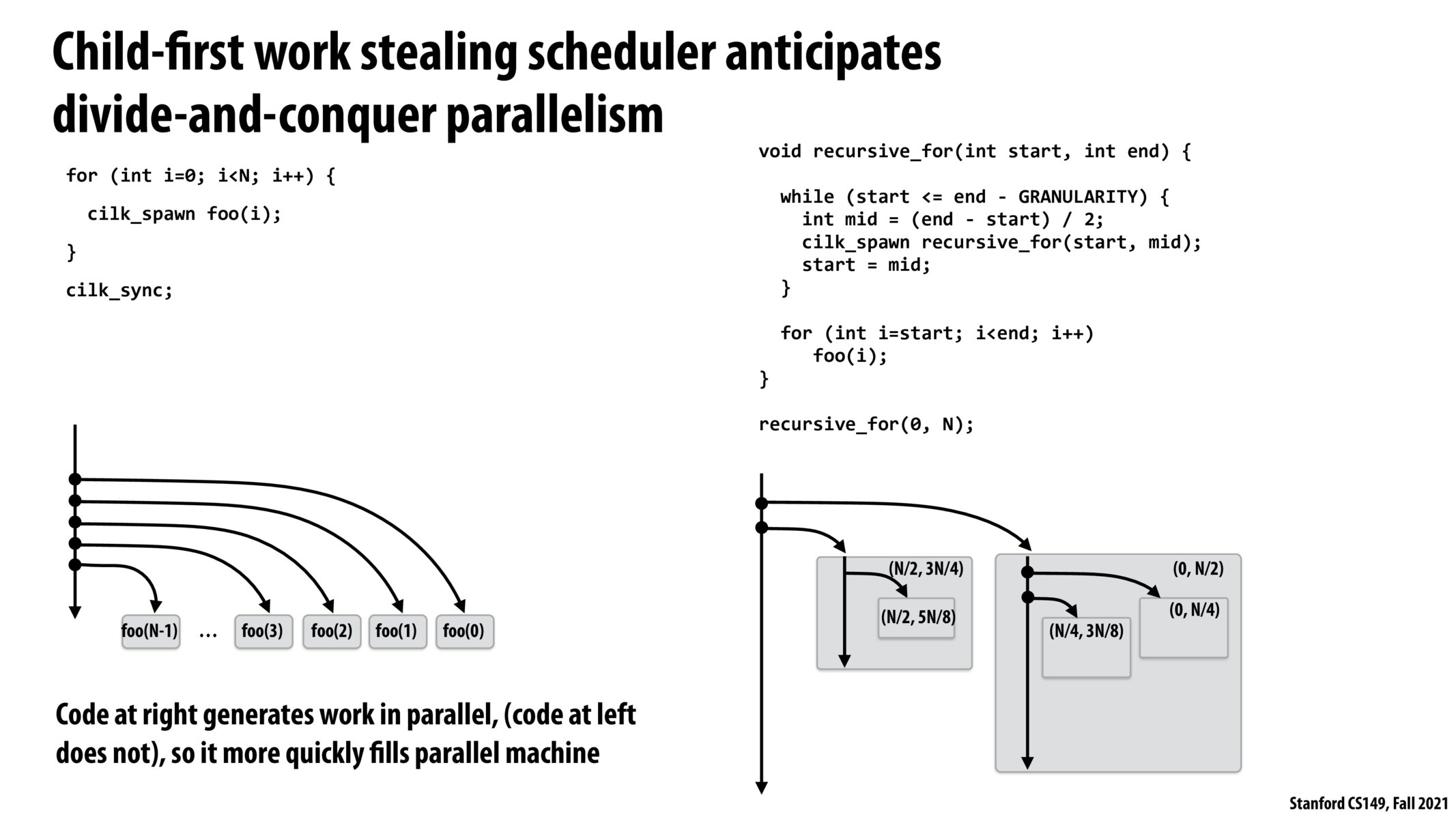


I think the point wasn't that the left code doesn't kick off any work to be done in parallel, but rather that it doesn't parallel-ly kick off more parallel work if that makes sense. So the code on the left just serially generates parallel work, but the right parallel-y generates more parallel work because it's recursive.

I didn't quite understand the motivation of why we want to do the child first rather than the continuation. The intuition I have right now is that queueing arbitrarily many child processes could create very large amounts of work - is that the main tradeoff?

@lindenli Agree. Another thing that Kayvon mentioned in class is that if it's in a setting where no parallel work can be scheduled, doing child-first will give us the exact order as running sequentially. This would give some nice properties for caching and data locality.
Please log in to leave a comment.
I couldn’t quite get why the code ot left doesn’t generate parallel work. From the diagram, it looks like every iteration of the loop is declared to be independent which means the processor can run them in parallel if there are resources. What am I missing here?