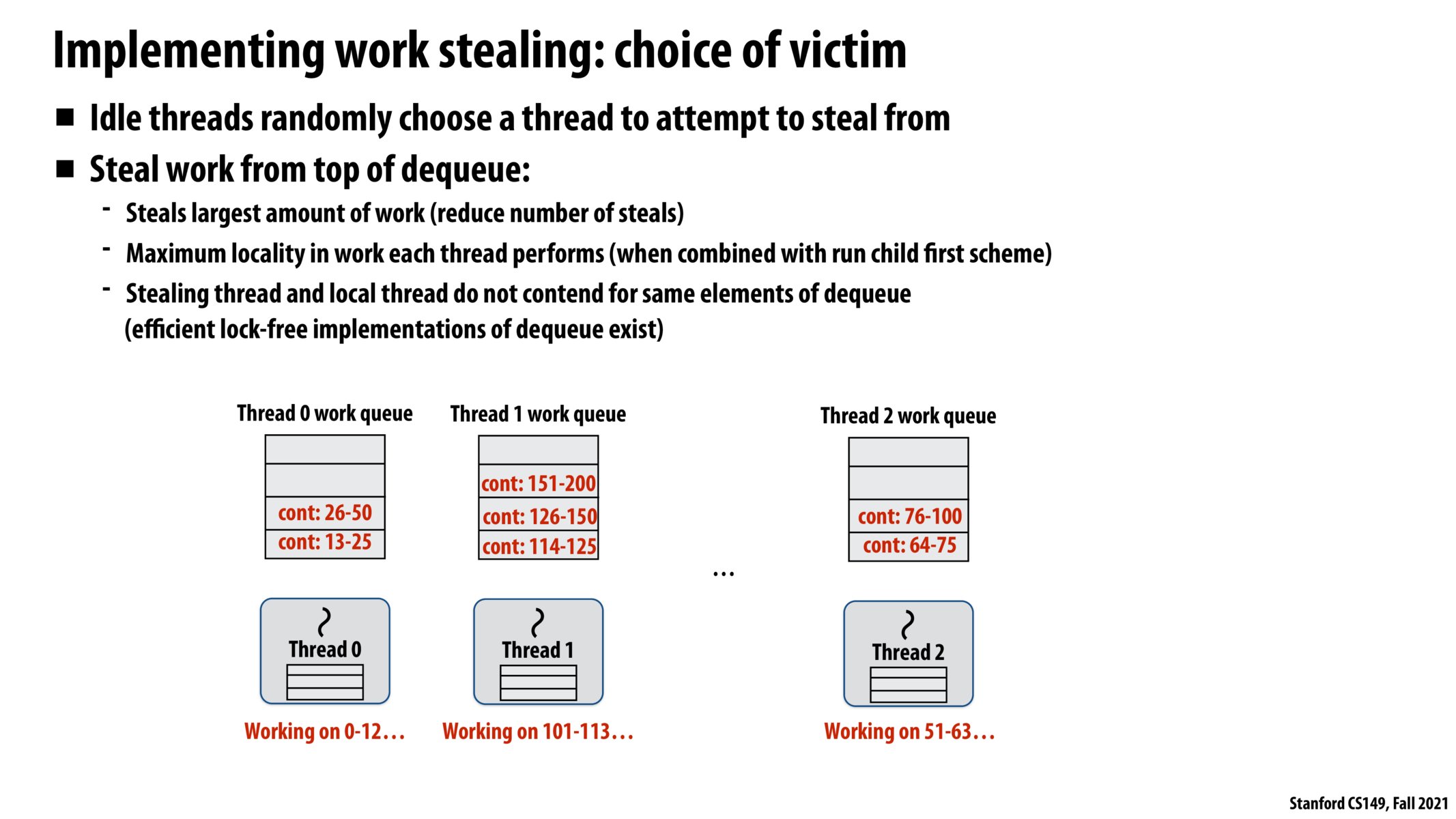


How does the work queue know which task is the most work so that the stealing thread will know which task to steal?

@jaez My understanding is it basically means we can keep the threads are having the maximum efficiency in this way. Because if thread 1 steals the work from the bottom, that would be the smallest piece of the work and thread 1 will quickly complete it and will need to steal again. But thread 0 will also need to steal again at this time (slightly earlier than thread 1 actually), so it might induce some overhead and lead to lower efficiency. I could be wrong though.
@pizza Kayvon talked about this a bit at the end of the lecture. Basically we are assuming we are partitioning the work in a reasonable way but not in a pathological way that we put the smallest work on the top of the queue.

@jaez I guess maximum locality is somewhat in these lines: Once the current thread finishes computing 0-12 elements and fetches work from the bottom of its local work queue, it now has to access 13-25 elements in the input array. These are closer to the location of 0-12 elements in the memory and therefore might have already been fetched into cache while bringing in 0-12 elements - thereby getting work from bottom of the local work queue increases the probability of cache hits. In the other case if a foreign thread steals from bottom of this work queue and tries to access 13-25 elements, it fetches the data from main memory (higher latency compared to cache) while this data may already be available in the local thread's cache since it already fetched 0-12 elements into its cache for its previous computation. Hope that makes sense. Please correct me if I am wrong or add if there is any other aspect of "maximum locality"

I'm still confused on how exactly taking work from the top of the dequeue is a good assumption. So the heuristic is to have the original thread do work from the newest thing which is best for memory, cache hits, etc. And then the other threads take the oldest thing since supposedly these are supposed to be the largest pieces of work. How exactly do we know that this is the case? Does it depend on implementation to know that the top of the dequeue will have the majority of the work in the task.

This stealing pattern does seem to create a lot of overhead. I'm wondering what's the benefit compared to a master/slave model, i.e. a scheduler that distributes tasks partitioned with the divide-and-conquer algorithm.
Please log in to leave a comment.
Could someone elaborate a bit on what "maximum locality" means in this case?