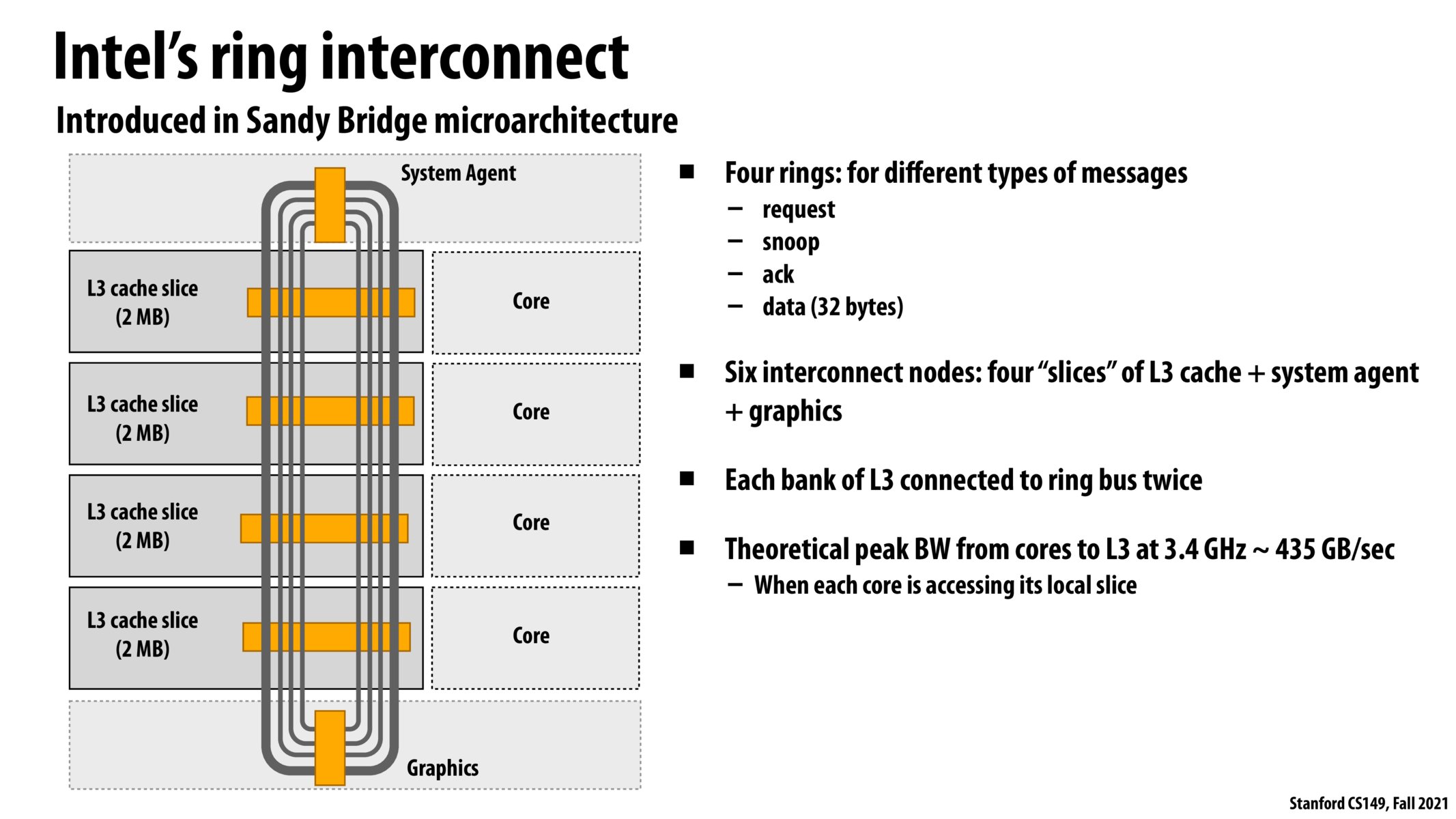


Following up with the above, does a ring of this configuration mean that data would reach some cores faster than others? Ie - if we have a write for x = 3 from x = 0, would that mean that the closest core adjacent to the writer would receive that information first, followed by all the others?

@juliob What I got from lecture is that messages travel one way in the loop and that the double loop structure is setup with loops in either direction such that the furthest a message has to travel to reach a specific other core is half of the loop.

what are the pros and cons of using a ring topology for the interconnect versus a mesh topology?

Found a very nice video that explains Intel's ring bus: https://www.youtube.com/watch?v=HGToWWne3do. Looks like that the ring design helps reduce latency, which is favorable to consumer-faced applications.

4 L3 cache slices is like having 4-way set associative?

@shivalgo, I think it isn't about associativity. I believe it's more like the NUMA discussions in terms of locality.

I hadn't thought much about the hardware implementation of a shared address space! I'm curious about how this works at an OS level (I don't know much about multi-core OS's). CS140 teaches us that a basic kernel has essentially universal access to machine memory. I'm curious -- to what extent would the details of hardware like this be exposed in an implementation of kernel address space? would the kernel still see a straightforward implementation of array-ish memory?

@tcr The kernel doesn't just see array-ish memory; it also has a certain degree of access to, for example, the cache (for example, in a virtual memory system, changes to TLB might necessitate a cache flush depending on the way the specific CPU's cache interacts with memory addresses). However, for general use it can indeed pretend that it's straightforward array-ish memory, because most of these implementation details are hidden at the processor level and exist to support the semantics of the instruction set architecture while allowing for a more performant underlying implementation.

How are memory bus's implemented? Is the MSI versioning an example of it?
Please log in to leave a comment.
So messages don't travel "around" the loop, per se, right? The wires still just turn HI/LOW really quickly right? So what is the idea of the ring and the double connections? Also, the professor mentioned "shortcutting", could this be expanded upon?