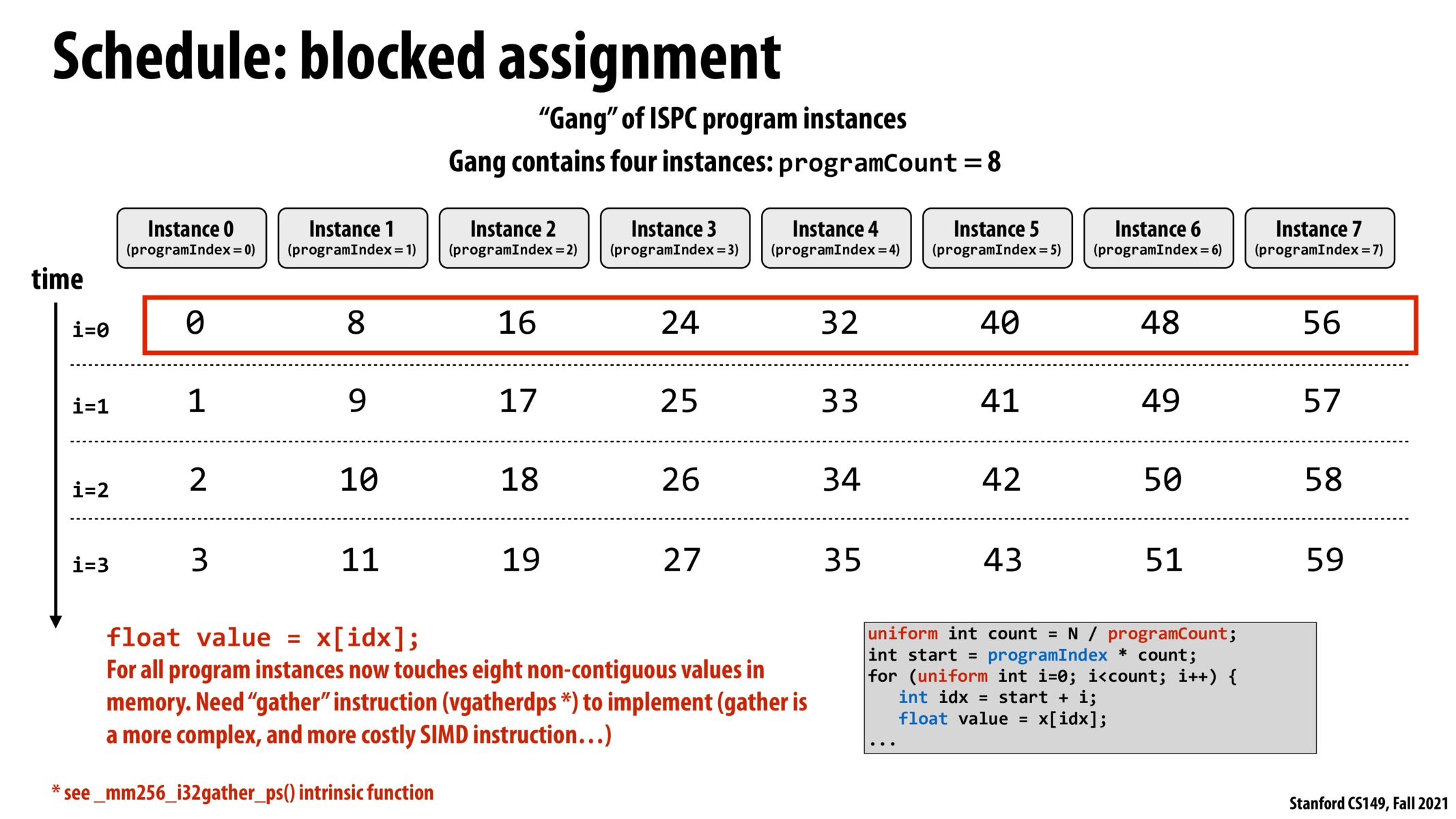


To confirm the point above, does this mean that at some time interval (say i = 0), we'd look to see what each of the program instances are doing on a corresponding element, and then put that all into a SIMD vector operation? In which case, since each program instance is working on a different 'block', the corresponding vector instruction would deal with different portions in memory, as opposed to a contiguous block in the previous example?

I agree with @AnonyMouse, I thought partitioning them into 1/8 chunks made more sense and was more efficient than interleaving the 8 program instances. The last slide made a lot of sense - the first instance can load and use SIMD to execute 8 addresses in one vector instruction. In this case, each instance is more spread out and we have to resort to more costly methods (gather instr) in order to load non-contiguous memory.

I'd be interested to know what real world programs would be better off using blocked assignments rather than interleaved assignments. Perhaps in a scenario where every 8th element has some sort of similarity/same instruction counts and some modulo assignments?

I think that since the i indexing the loop is uniform it is true that each iteration of the loop is synchronized across the program instances in the gang. This is the reason why a blocked assignment requires a gather instruction versus reading from a contiguous interval in memory.
However, I believe in certain non-ISPC formulations where the loop iterations are not synchronized between program instances it may be more beneficial to do a blocked assignment (e.g. could reduce communication needs across boundaries versus interleaved assignment).

In HW1, I tried modifying the saxpy code to have each ISPC program instance operate on a block, and it was incredibly slow. This was to be expected because of the gather instructions which defeated the point of SIMD. Well at least now I know how the gather function works in TensorFlow.
Please log in to leave a comment.
It was kinda counter-intuitive how that giving each instance a contiguous block of memory resulted in more cost VS dividing one contiguous chunk over all instances at a time but it makes sense once we learn that the underlying implementation makes every instance basically an element in a vector register (I think?) and so a load of a contiguous block of memory to supply the vector with all those instances is less costly than fetching an element from region 1 to instanced 1, element from region 2 to instance 2, etc.