

Why are RDDs immutable? I feel like it would be easier on memory management if you could edit an RDD instead of having to make a new one for each step.

@shaan0924 just because we are applying transformations and assigning to a new RDD does not require making a new RDD under the hood, the compiler might optimize it away. I believe the immutability makes it easier to use them as checkpoints, since if you are in the middle of editing a RDD which you have specified you want to keep and something goes wrong, you could lose the whole RDD.

As mentioned already, immutability offers many advantages and optimizations that can occur. I would think of this concept as an invariant, that Spark uses RDD to transform or manipulate a fix set of data.
It wouldnt make much sense to be filtering on a RDD and while filtering took place, the RDD would be modified by an external action. Then the entire logic of Spark would become increasingly complicated.

@sanjayen I don't think that RDDs are generated on a per-node basis, since they're an abstraction representing a distributed (generally across multiple nodes) collection of elements. Also, within this abstraction, since an RDD lives across multiple nodes (with partitions of the RDD actually existing in the nodes) I wouldn't think that it matters which node "created" an RDD. It does appear that the master node has some understanding of what partitions of the RDD live on each node, and in the case of node failure, it will recompute the RDD partitions that were on the failed node (http://35.227.169.186/cs149/fall21/lecture/spark/slide_48).

@nassosterz What are some of the advantages and optimizations that occur from immutability? Does it help with storage in any way?

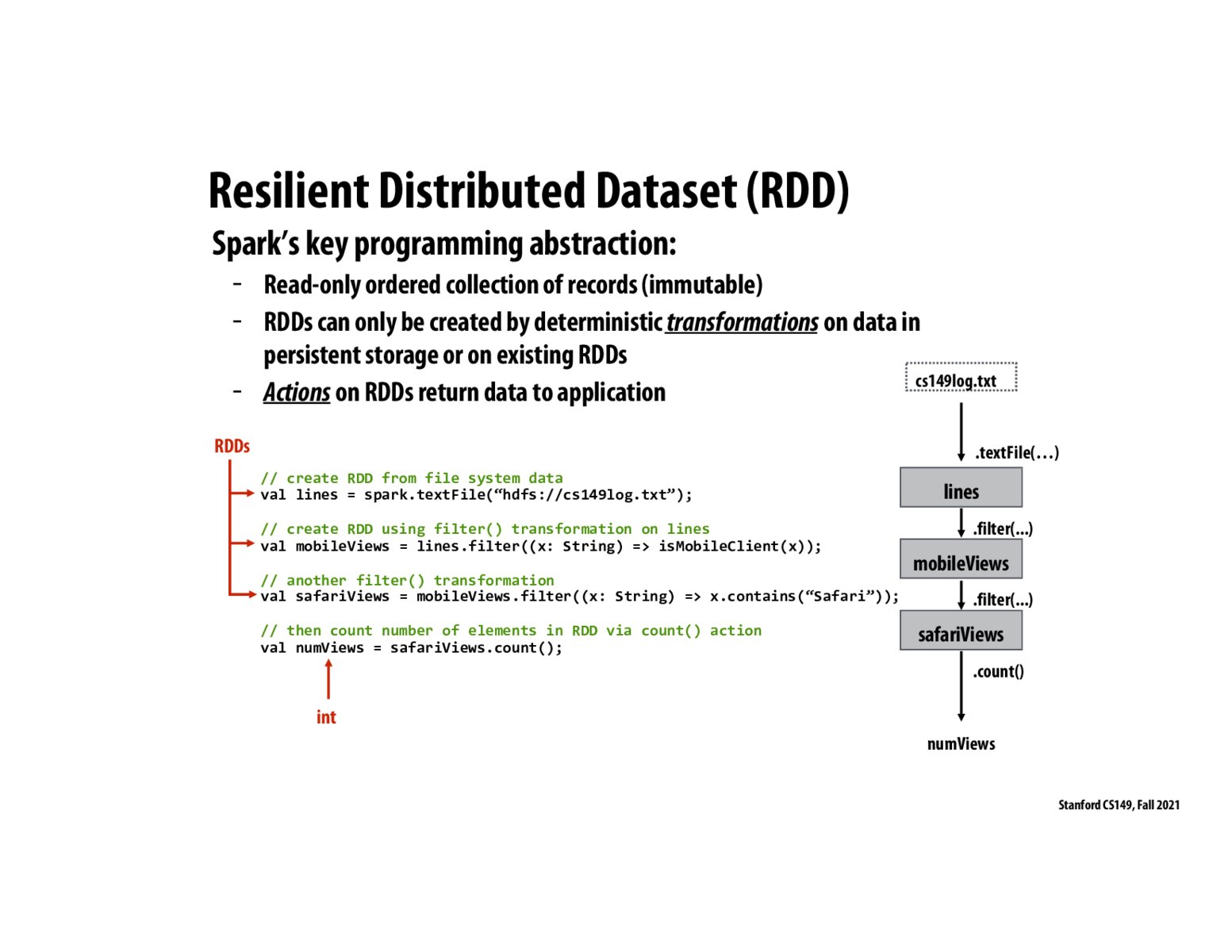
Something that helped me better understand RDD's is to simply think of them as sequences. We can think of transformations on RDD's as the data-parallel primitives that Kayvon covered in the previous lecture such as map and reduce. Again, it's important to note that RDD's are immutable in order to ensure proper execution despite possible node failures.

What is the best way to think of how Spark uses RDDs? Is every step essentially similar to like the mapping step inside of map reduce, especially when the Spark abstraction filters a RDD to create a new RDD, up until the point that the count function, the reduce, is applied?
Please log in to leave a comment.
A few clarification questions: does an RDD provide a complete snapshot of the result of a transformation? E.g. if we had an input file with lines of text, an RDD produced by using a filter() transformation would store a file with lines of text matching the filter? Also, are RDDs generated on a per-node basis? If so, is there a way of checking which node created an RDD in case of node failure?