

Spark uses lazy execution for these operations, which means that it will only do transformations when users want to store it or see the result. This means that Spark usually doesn't need to compute these intermediate RDDs (unless you tell it to). Instead, it merges the lineage and combines operations together. This could also increase arithmetic intensity

The question of "do we completely have to materialize a dependee step before a depender step can execute" seems similar to whether we can pipeline these load/map/filter stages by further dividing them into stages. Is this line of thinking what Prof. Kunle was trying to convey here?

Is there an equivalent of ProgramCount or ThreadIndex variable that we could access to customize the behavior of different nodes?

I also found this section fairly confusing!
It seems like in just slightly more complicated pipelines (like those shown earlier in the lecture), tracking lazy execution dependencies in a cluster setting like this could be expensive in terms of communication. How do we handle this kind of thing? Or if we split a computation at some intermediate RDD, would the default be to store that in memory (i.e. do dynamic programming?) or not.

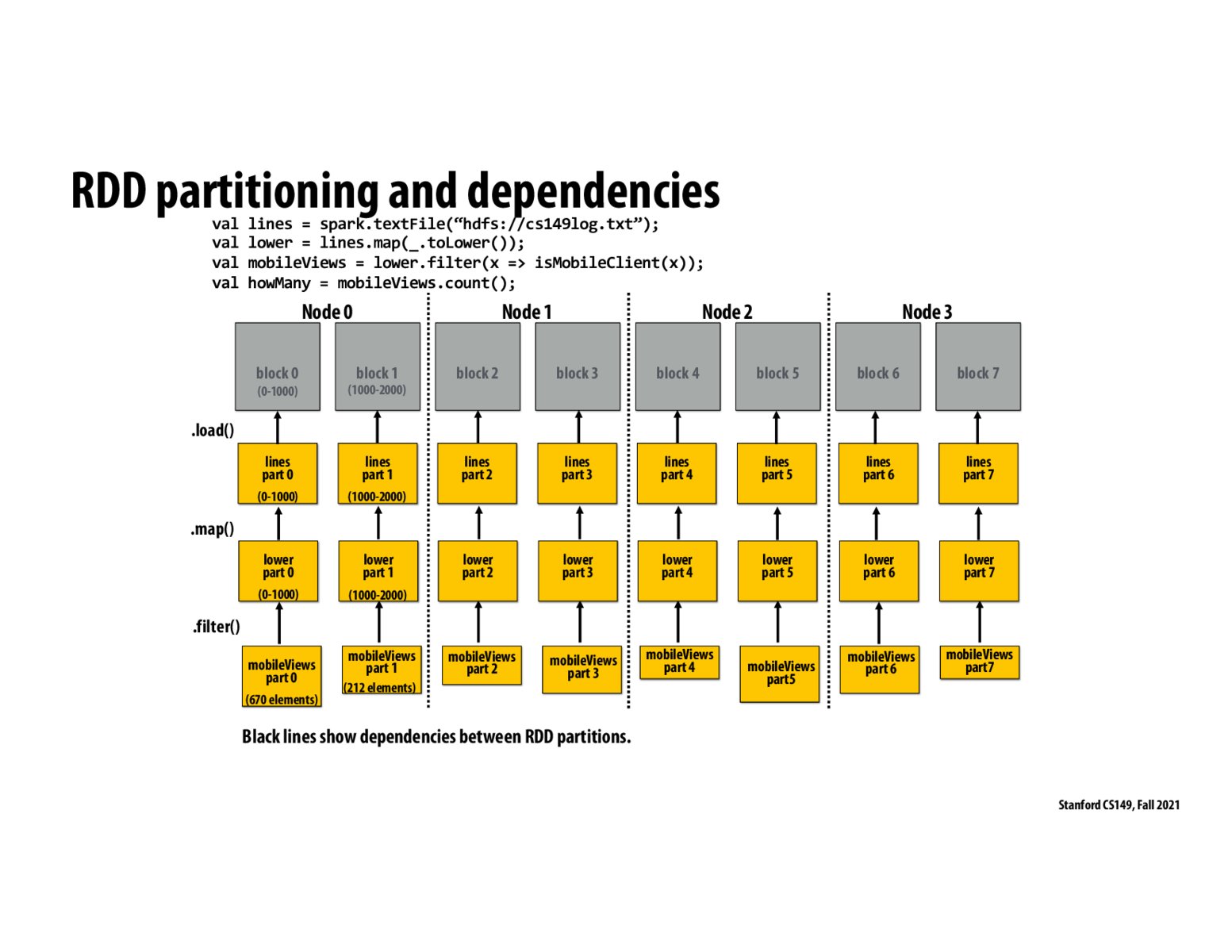
If each dotted line is a partition, and each arrow is a dependency, how do the arrows show dependencies between partitions, as described in the slide? I assumed this diagram meant no dependencies can exist between partitions, and can exist only within partitions.

Do we create a new RDD with every function call?
Please log in to leave a comment.
I found this section of lecture to be very confusing, several questions were posed but never answered. So, in order to not store (# operations) * (data size) in memory, you are able to move onto say, mobileViews part 0 before lower part 1 - 7 is done. Does this mean that when you begin mobileViews part 0 using lower part 0, you delete lines part 0? In other words, do you only keep in the working set the previous RDD partition this operation needs?