
As a follow-up, when, if eer, is the info written back to disk?

@potato, my understanding is that we find that fault tolerance can be achieved by tracing back the lineage to retrieve a previous state of the RDD. In other words, upon a crash, we can go back in the lineage of deterministic transformations made to the RDDs until we are able to begin computation once again. This is a memory-efficient fault-tolerance mechanism since log files of transformations are low in memory to maintain.

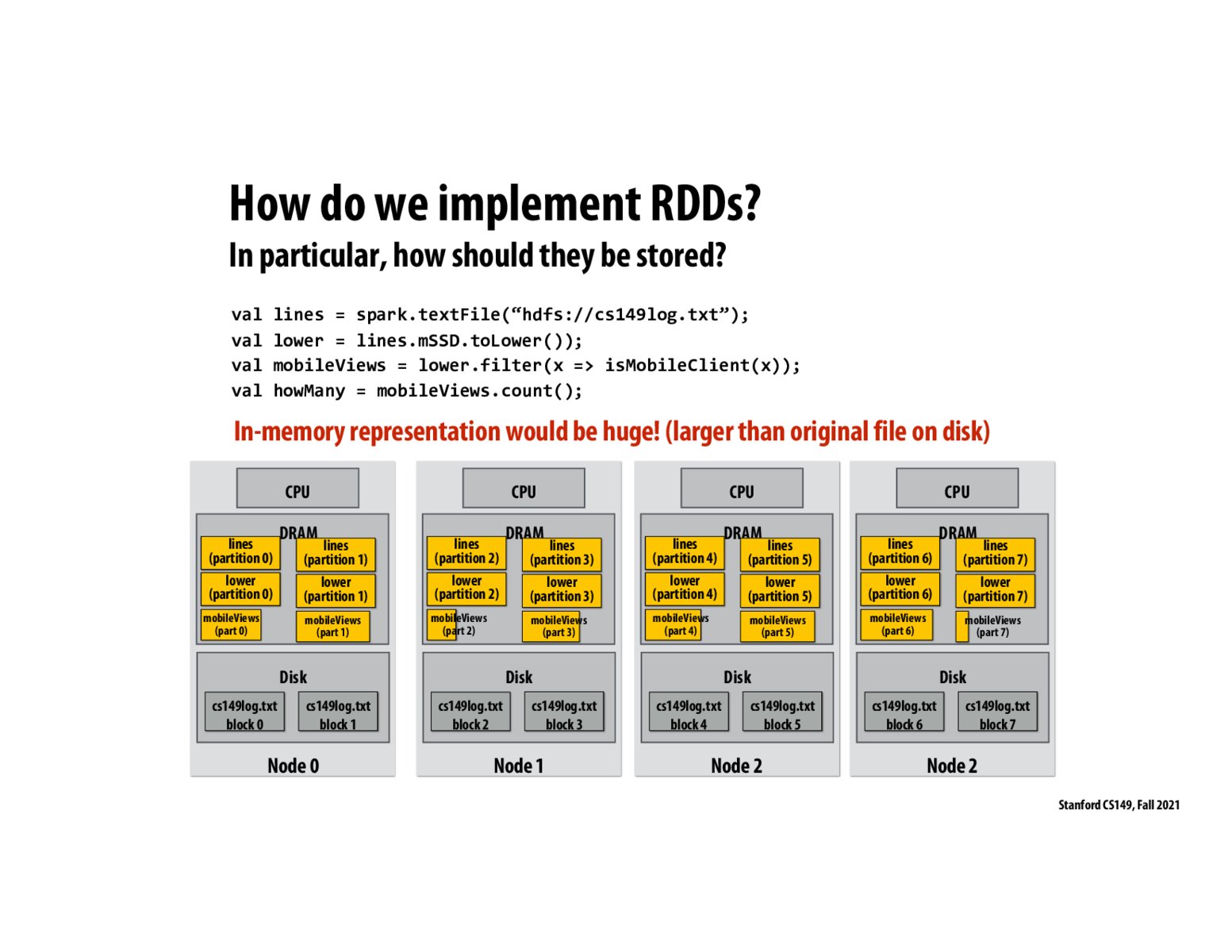
What is a partition and why are there partitions?

Also wondering this, is it because partitions are needed because there may be multiple physical RAM sticks? Why can't this be abstracted away?

Could we store all the "lines" in one node, all the "lowers" in another node, etc? Or does that make it not fault tolerant anymore?

Do we need to make copies of lines when storing them, to ensure that if one node fails, the lines are still available somewhere else?

I don't really understand what the main advantage of using RDDs is? Is it the fact that it allows for the read-only operations to be parallelized across machines or is there more to it? The way I understand it at least is that RDDs allow you to perform parallel computation tasks on datasets over clusters, but I'm assuming work like this had been done before spark.
Please log in to leave a comment.
How is this fault-tolerant if they're still in-memory? Wouldn't they still be wiped if memory died?